微软开源的 VibeVoice 项目为语音合成领域带来了新的可能性。这个框架专注于生成富有表现力的长篇幅、多说话人对话音频,例如播客。它解决了传统文本转语音系统在可扩展性、说话人一致性和自然话轮转换方面的核心难题。
目前,VibeVoice 包含两个主要模型变体。一个是长篇幅多说话人模型,能够合成长达 90 分钟、包含最多 4 个不同说话人的对话或单人语音,突破了以往模型通常 1-2 个说话人的限制。另一个是实时流式 TTS 模型,它能在约 300 毫秒内产生第一段可听语音,并支持流式文本输入,专为低延迟的单人实时语音生成而设计。
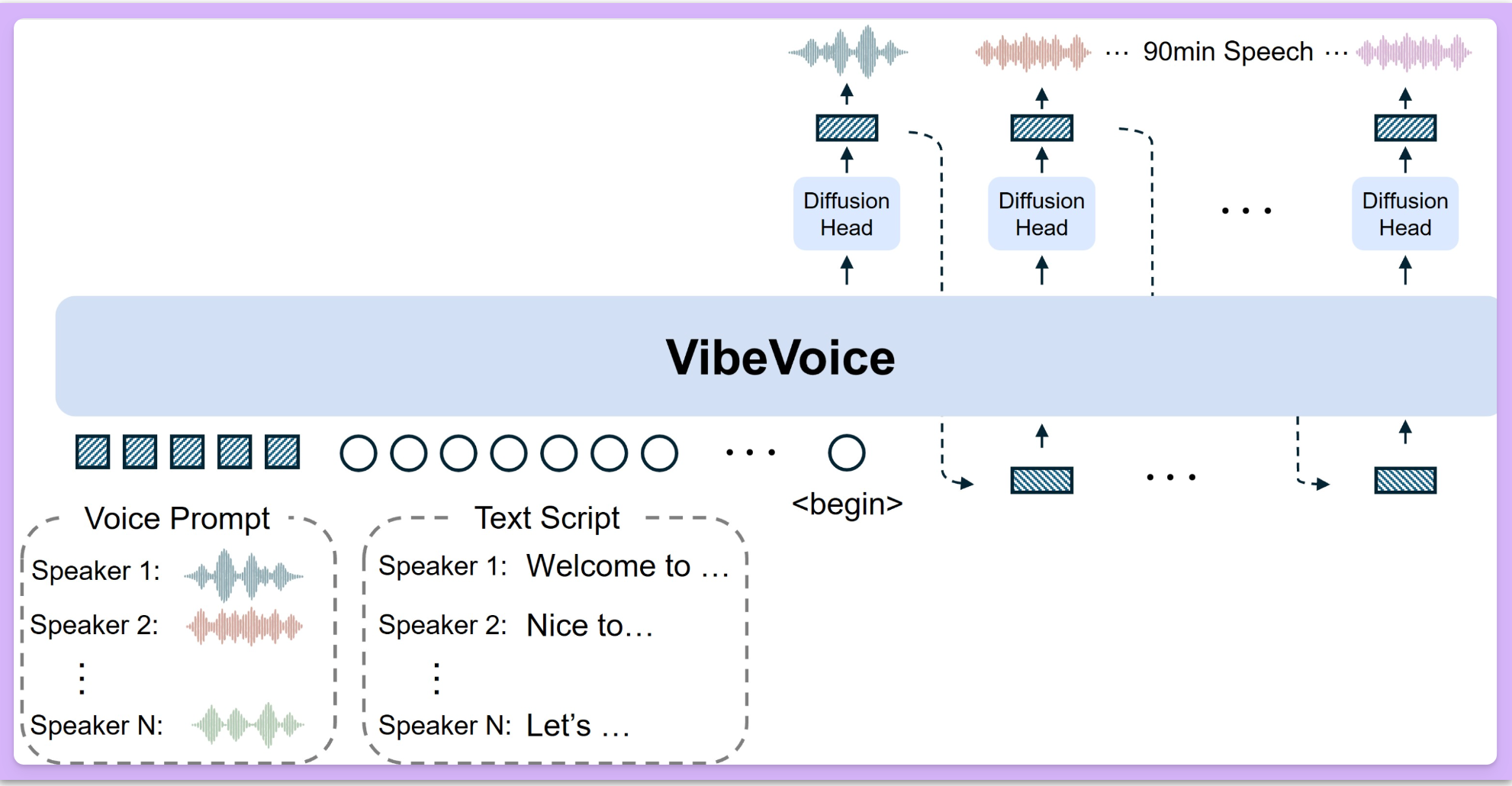
VibeVoice 的核心创新在于使用了工作在超低帧率 7.5 Hz 下的连续语音分词器。这些分词器在高效保持音频保真度的同时,显著提升了处理长序列的计算效率。项目采用了一种“下一词元扩散”框架,利用大语言模型来理解文本上下文和对话流,并使用扩散头来生成高保真度的声学细节。
快速开始与安装
要体验 VibeVoice,最便捷的方式是通过其提供的 Colab 笔记本。对于希望本地部署的研究者和开发者,则需要按照以下步骤搭建环境。
首先,克隆项目仓库并安装必要的依赖。建议使用 Python 虚拟环境以避免依赖冲突。
git clone https://github.com/microsoft/VibeVoice.git
cd VibeVoice
pip install -r requirements.txt
安装过程可能需要一些时间,具体取决于网络环境和硬件配置。完成后,便可以通过提供的脚本加载预训练模型并进行推理。
模型使用与配置
VibeVoice 提供了不同的模型用于不同的场景。理解每个模型的能力和输入输出格式是关键。长篇幅模型适合生成播客、有声书等内容,而实时模型则适用于需要即时语音反馈的交互式应用。
运行基础推理的代码结构通常如下所示。你需要准备文本输入和相应的说话人配置。
from vibevoice import VibeVoicePipeline
# 初始化管道,指定模型路径或 Hugging Face 标识符
pipeline = VibeVoicePipeline.from_pretrained("microsoft/VibeVoice-long-form")
# 准备输入:文本和说话人ID列表
input_text = "Hello, welcome to the podcast. Today we will discuss AI."
speaker_ids = [0, 1] # 假设两个说话人交替
# 生成音频
audio_output = pipeline.generate(input_text, speaker_ids=speaker_ids)
对于实时流式模型,使用方式有所不同,它设计为接收连续的文本流。项目文档中提供了基于 WebSocket 的示例,可以启动一个实时演示服务。
# 根据文档启动实时 WebSocket 演示服务器
python demo/websocket_server.py --model_path ./models/realtime-0.5b
不同的任务对模型参数有不同要求。下表概括了两种主要模型的关键特性和典型应用场景:
| 特性 | 长篇幅多说话人模型 | 实时流式 TTS 模型 |
|---|---|---|
| 主要用途 | 播客、对话模拟、长内容生成 | 实时交互、语音助手、流式响应 |
| 最大时长 | 约 90 分钟 | 支持持续流式输入 |
| 说话人数 | 最多 4 人 | 单人 |
| 首次语音延迟 | 依赖生成长度 | ~300 毫秒 |
| 输入模式 | 完整文本 | 流式文本块 |
| 输出模式 | 完整音频文件 | 流式音频块 |
高级功能与多语言支持
除了基础的英语和中文合成,VibeVoice 近期还添加了九种语言的实验性说话人支持,包括德语、法语、日语、韩语等。
项目的一个突出亮点是能够生成带有自发歌唱元素的语音,这在传统 TTS 系统中较为罕见。
它还能处理复杂的、包含多人交替的长对话,并尝试保持每个说话人声音的一致性和对话的自然流畅度。
如何利用这些高级功能?关键在于构造合适的输入文本和说话人序列。对于包含特定风格如歌唱的段落,可能需要在文本中进行隐式或显式的标注,模型会根据其训练数据中的模式进行模仿。
潜在风险与使用边界
强大的技术总伴随着责任。VibeVoice 生成的高质量合成语音存在被滥用于制造深度伪造内容、进行欺诈或传播虚假信息的风险。因此,使用者必须确保输入文本的可靠性,核查生成内容的准确性,并避免以误导性的方式使用产出内容。
模型本身也存在一些局限性。它目前仅专注于语音合成,不处理背景噪音、音乐或其他音效。当前的对话模型也没有显式地建模或生成对话中可能出现的语音重叠片段。对于英文和中文以外的语言输入,可能会产生不可预期的音频输出。
这些限制提醒我们,为什么项目团队强调 VibeVoice 目前仅用于研究和开发目的,不建议在没有进一步测试和开发的情况下将其用于商业或真实世界应用。遵守所有适用法律和法规,并在分享 AI 生成内容时披露其来源,是最基本的实践准则。
技术的演进速度很快,从项目的星标历史图就能看出社区对它的关注。作为一个开源研究框架,VibeVoice 的进步依赖于社区的协作、负责任的实验和坦诚的反馈。无论是尝试其实时演示,还是探索其长文本生成边界,每一次测试都在帮助界定这项技术的可能性与伦理框架。
开发必备:API 全流程管理神器 Apifox
介绍完上文的内容,我想额外介绍一个对开发者同样重要的效率工具 —— Apifox。作为一个集 API 文档、API 调试、API 设计、API 测试、API Mock、自动化测试等功能于一体的 API 管理工具,Apifox 可以说是开发者提升效率的必备工具之一。
如果你正在开发项目需要进行接口调试,不妨试试 Apifox。注册过程非常简单,你可以直接在这里注册使用。
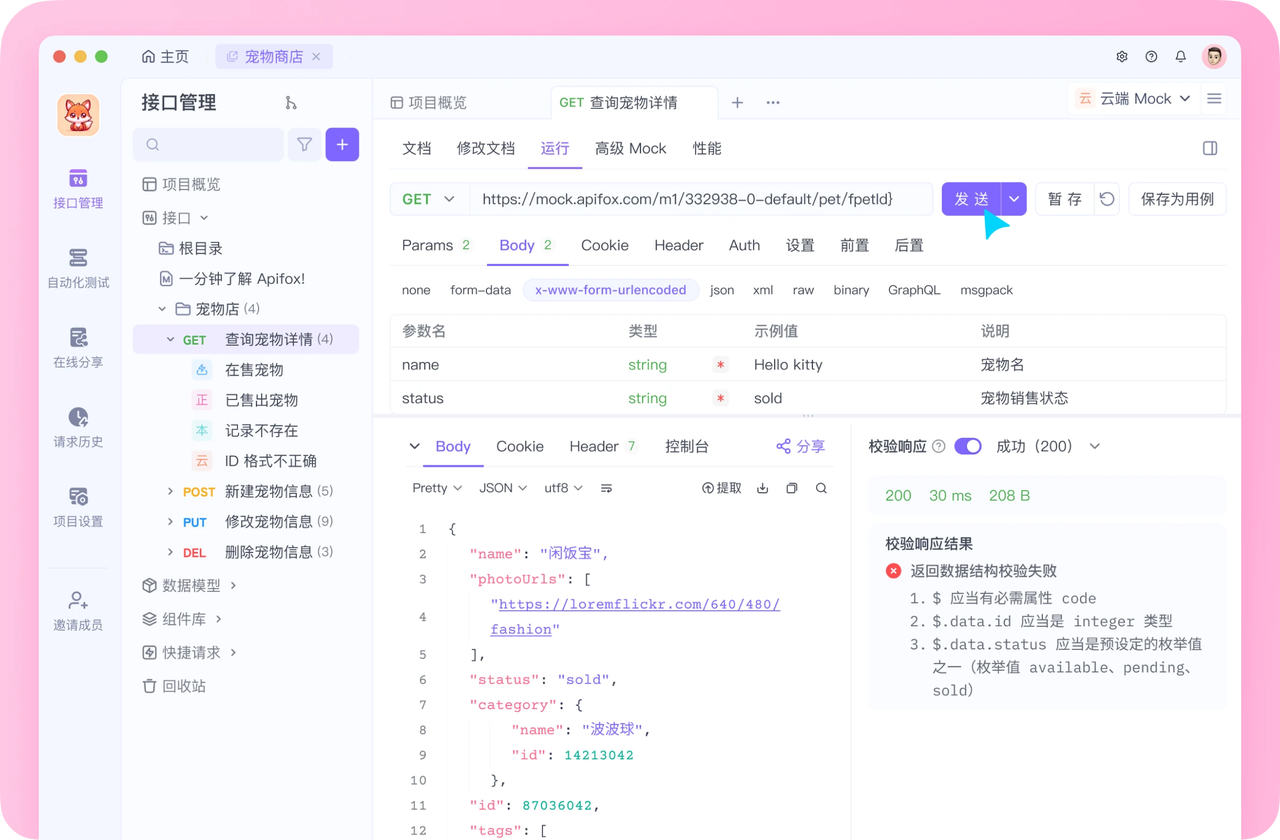
注册成功后可以先看看官方提供的示例项目,这些案例都是经过精心设计的,能帮助你快速了解 Apifox 的主要功能。
使用 Apifox 的一大优势是它完全兼容 Postman 和 Swagger 数据格式,如果你之前使用过这些工具,数据导入会非常方便。而且它的界面设计非常友好,即使是第一次接触的新手也能很快上手,快去试试吧!