Google的Gemini模型家族迎来了新成员Gemini 3 Flash。这是一个在速度与成本效率上表现突出的模型,尤其适合需要快速响应的应用场景。理解其API调用方式是将其集成到项目中的第一步。
模型特性与定位
Gemini 3 Flash的设计目标明确,在模型能力矩阵中占据了独特的位置。它并非追求极致的复杂推理能力,而是在响应速度和性价比上做到了优秀平衡。
下面的表格对比了Gemini 3 Flash与同系列其他模型的一些典型特征,这有助于在项目选型时做出判断。
| 特性维度 | Gemini 3 Flash | Gemini 3 Pro (对比参考) |
|---|---|---|
| 核心优势 | 极低的延迟,高吞吐量 | 更强的复杂推理能力 |
| 适用场景 | 实时对话、内容摘要、快速分类 | 代码生成、逻辑推理、多步骤任务 |
| 输入上下文 | 100万tokens | 200万tokens |
| 输出方式 | 文本 | 文本 |
从表格可以看出,当应用场景对响应时间敏感,或需要处理大量并发请求时,Gemini 3 Flash是一个理想的选择。它的出现让开发者可以在预算范围内,为终端用户提供更流畅的交互体验。
调用 Gemini 3 Flash API 接口
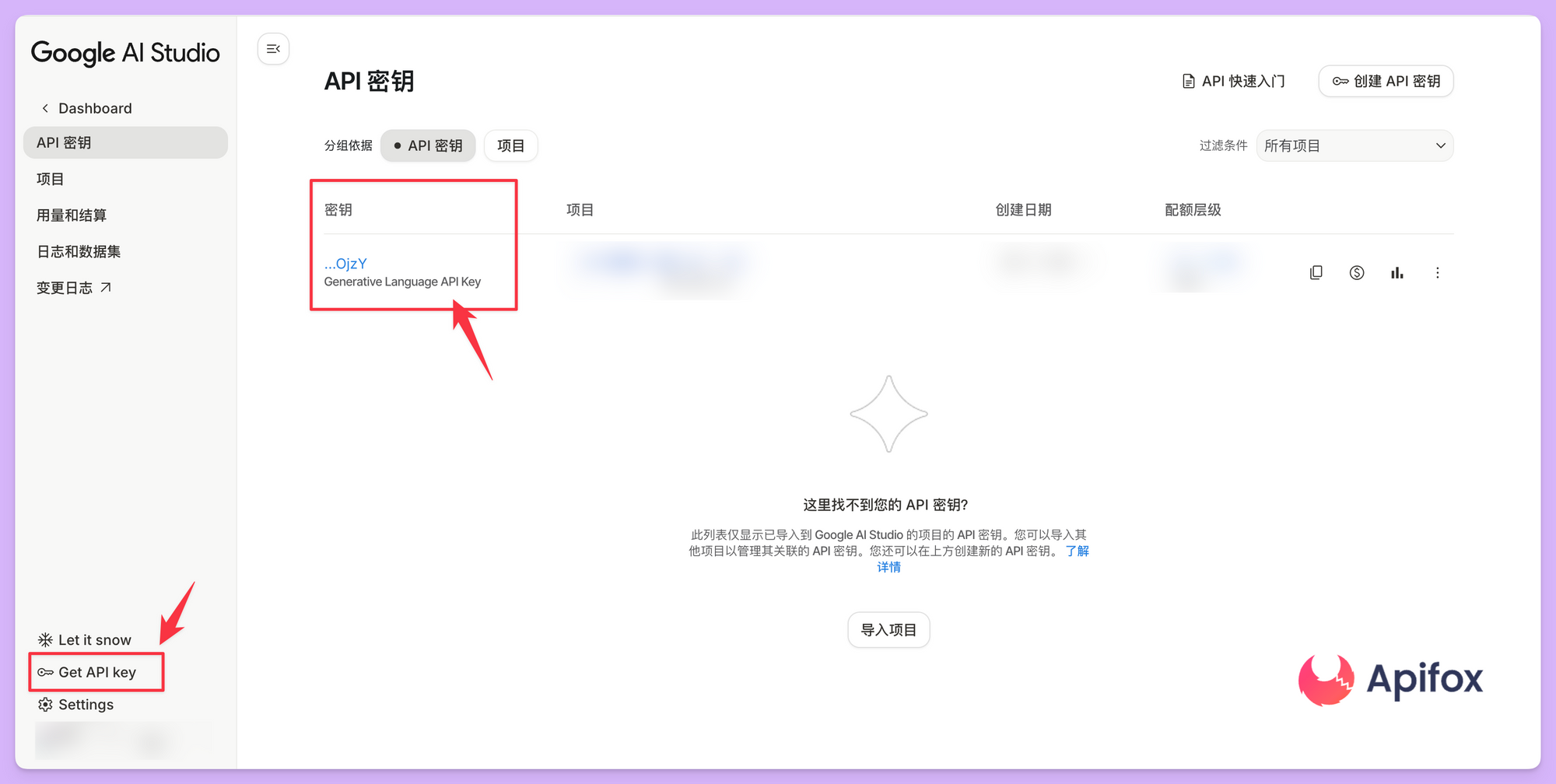
获取与配置API密钥
调用任何Gemini API的第一步是获取通行证。访问Google AI Studio,在账户设置中能够生成专属的API密钥。这个密钥是访问服务的凭证,需要妥善保管。
接下来的工作是在代码中配置这个密钥。通常的做法是通过环境变量来管理,避免将敏感信息硬编码在代码库中。
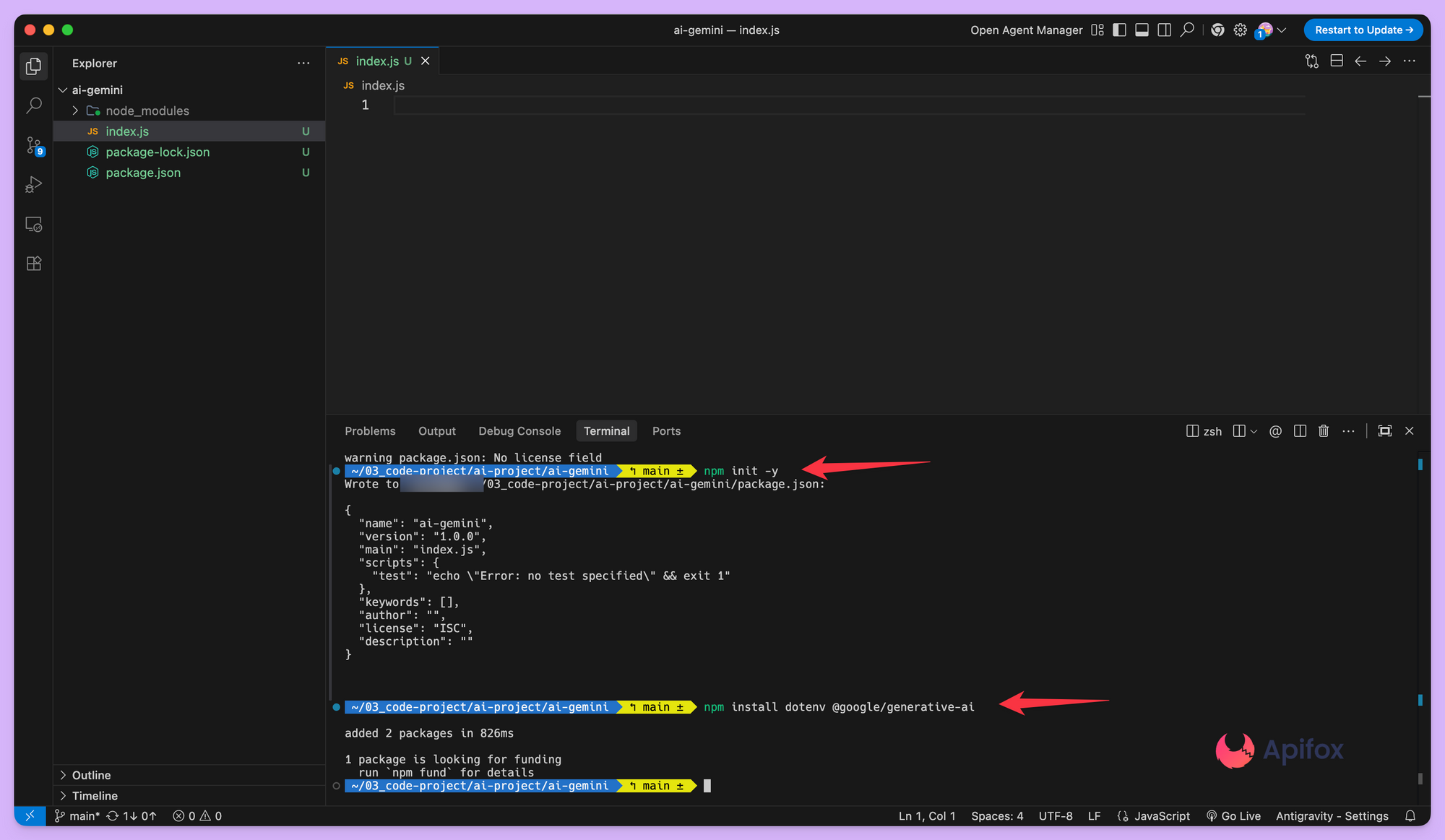
安装依赖
在Node.js项目中,可以通过dotenv包来加载环境变量。安装必要的依赖是项目准备的一部分。
npm install @google/generative-ai dotenv
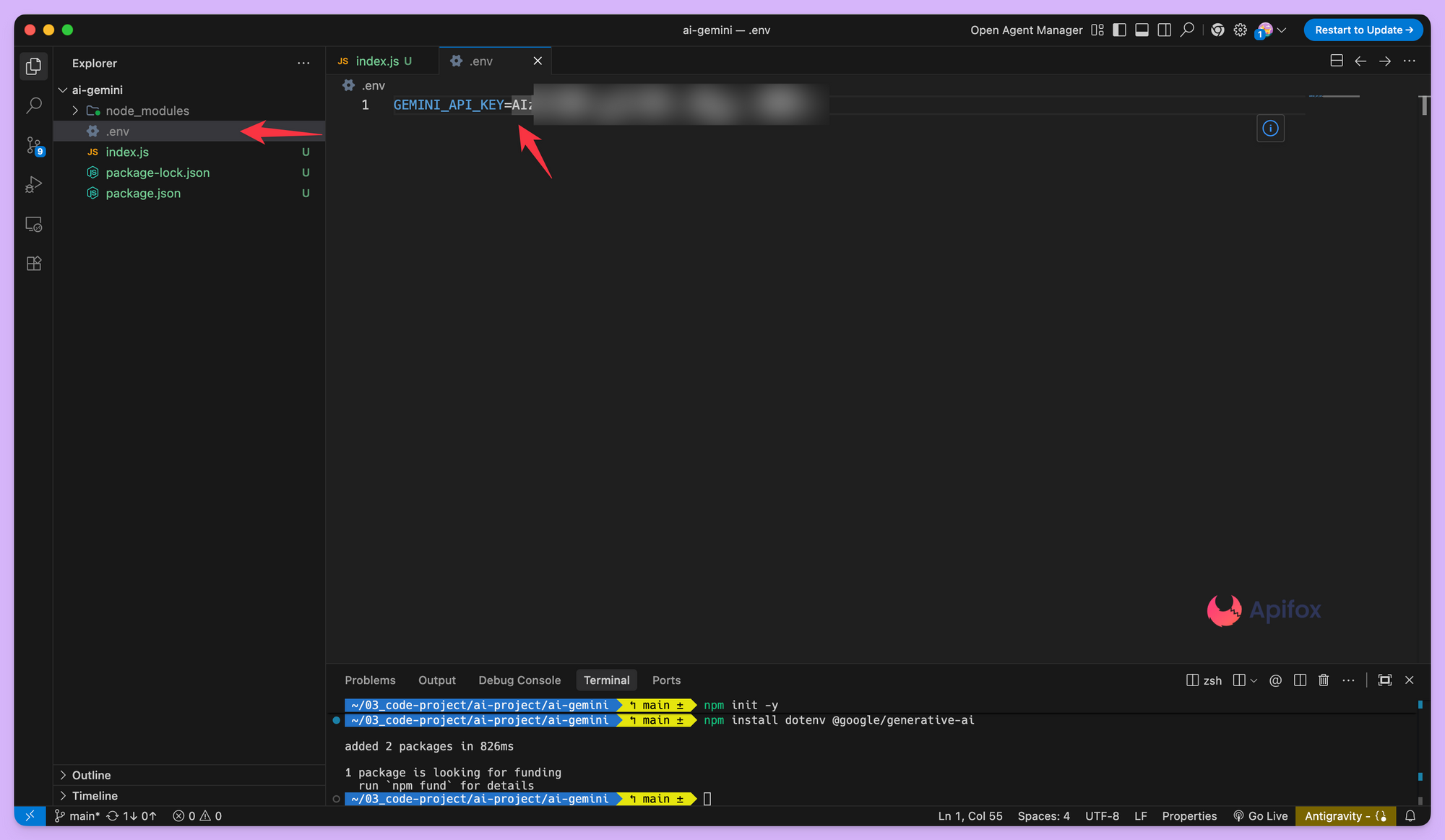
完成安装后,在项目根目录创建.env文件,并将API密钥填入。
GEMINI_API_KEY=your_api_key_here
注意: .env 文件不要提交到代码仓库,通常需要加入 .gitignore 文件里忽略它。
运行代码
新建一个 index.js文件, 代码中通过process.env来读取这个变量,初始化GenAI客户端。完整内容如下:
import dotenv from "dotenv";
import { GoogleGenerativeAI } from "@google/generative-ai";
// 加载环境变量
dotenv.config();
// 从环境变量中读取 API Key
const apiKey = process.env.GEMINI_API_KEY;
if (!apiKey) {
throw new Error("GEMINI_API_KEY is not set");
}
// 初始化 GenAI 客户端
const genAI = new GoogleGenerativeAI(apiKey);
// 指定使用的模型
const model = genAI.getGenerativeModel({
model: "gemini-3-flash-preview",
});
// 发起一次基础文本生成请求
async function run() {
const prompt = "用一句话解释什么是 RESTful API";
const result = await model.generateContent(prompt);
// 获取模型返回的文本
const text = result.response.text();
console.log(text);
}
run().catch(console.error);
在终端执行:
node index.js如果环境变量和依赖都配置正确,控制台会直接输出 Gemini 生成的文本内容。
探索高级生成参数
基础调用满足了简单需求,但实际应用往往需要更多控制。Gemini API提供了一系列参数来调整生成行为,例如temperature和maxOutputTokens。
temperature参数控制输出的随机性。值越低,输出越确定和可预测;值越高,输出越有创造性。对于需要稳定答案的任务,较低的temperature更合适。
maxOutputTokens则限定了模型响应内容的最大长度。合理设置这个值可以控制响应篇幅,避免生成过于冗长的内容,同时也是一种成本控制手段。
将这些参数整合到调用中,代码会变成下面这样。
import dotenv from "dotenv";
import { GoogleGenerativeAI } from "@google/generative-ai";
// 加载环境变量
dotenv.config();
const apiKey = process.env.GEMINI_API_KEY;
if (!apiKey) {
throw new Error("GEMINI_API_KEY is not set");
}
// 初始化 GenAI 客户端
const genAI = new GoogleGenerativeAI(apiKey);
// 获取模型,并配置生成参数
const model = genAI.getGenerativeModel({
model: "gemini-3-flash-preview",
generationConfig: {
temperature: 0.3, // 控制随机性,值越低越稳定
maxOutputTokens: 200, // 限制最大输出长度
},
});
// 发起一次文本生成请求
async function run() {
const prompt = "用简明易懂的语言解释什么是 RESTful API";
const result = await model.generateContent(prompt);
const text = result.response.text();
console.log(text);
}
run().catch(console.error);
通过调整这些配置,生成的文本风格和长度会更贴合产品的具体需求。不同的参数组合会产生显著不同的效果,这值得在开发过程中进行多次试验。

处理多轮对话上下文
许多交互式应用依赖于对话历史。Gemini API支持以消息列表的形式发送多轮对话内容,从而实现有记忆的对话。每次调用时,需要将整个对话历史传递给模型。
对话中的每条消息都有一个角色,通常是user或model。通过按顺序组织这些消息,模型就能理解当前的对话上下文,并给出连贯的回复。
import dotenv from "dotenv";
import { GoogleGenerativeAI } from "@google/generative-ai";
dotenv.config();
const genAI = new GoogleGenerativeAI(process.env.GEMINI_API_KEY);
const model = genAI.getGenerativeModel({
model: "gemini-3-flash-preview",
generationConfig: {
temperature: 0.3,
maxOutputTokens: 2000,
},
});
async function run() {
const result = await model.generateContent({
contents: [
{
role: "user",
parts: [{ text: "什么是 RESTful API?" }],
},
{
role: "model",
parts: [{ text: "RESTful API 是一种基于 HTTP 设计的接口风格,用于客户端与服务器之间的数据交互。" }],
},
{
role: "user",
parts: [{ text: "那它和传统 RPC 接口相比有什么优势?" }],
},
],
});
console.log(result.response.text());
}
run().catch(console.error);
在这个例子中,模型首先被设定了角色,然后基于这个角色背景回答用户的新问题。这种模式非常适合构建聊天机器人或需要持续上下文的任务。管理好对话历史的长度很重要,过长的历史可能会增加token消耗并影响模型对最近信息的关注度。
流式输出
如果要流式输出(Streaming),核心变化只有一个:
把 generateContent 换成 generateContentStream,然后一边接收、一边输出模型返回的内容。
import dotenv from "dotenv";
import { GoogleGenerativeAI } from "@google/generative-ai";
dotenv.config();
const genAI = new GoogleGenerativeAI(process.env.GEMINI_API_KEY);
const model = genAI.getGenerativeModel({
model: "gemini-3-flash-preview",
generationConfig: {
temperature: 0.3,
maxOutputTokens: 800,
},
});
async function run() {
const stream = await model.generateContentStream({
contents: [
{
role: "user",
parts: [{ text: "什么是 RESTful API?" }],
},
{
role: "model",
parts: [{ text: "RESTful API 是一种基于 HTTP 协议设计的接口风格。" }],
},
{
role: "user",
parts: [{ text: "它为什么适合前后端分离的架构?" }],
},
],
});
// 流式读取模型输出
for await (const chunk of stream.stream) {
const text = chunk.text();
if (text) {
process.stdout.write(text);
}
}
console.log("\n--- 完成 ---");
}
run().catch(console.error);
开发必备:API 全流程管理神器 Apifox
介绍完上文的内容,我想额外介绍一个对开发者同样重要的效率工具 —— Apifox。作为一个集 API 文档、API 调试、API 设计、API 测试、API Mock、自动化测试等功能于一体的 API 管理工具,Apifox 可以说是开发者提升效率的必备工具之一。
如果你正在开发项目需要进行接口调试,不妨试试 Apifox。注册过程非常简单,你可以直接在这里注册使用。
注册成功后可以先看看官方提供的示例项目,这些案例都是经过精心设计的,能帮助你快速了解 Apifox 的主要功能。
使用 Apifox 的一大优势是它完全兼容 Postman 和 Swagger 数据格式,如果你之前使用过这些工具,数据导入会非常方便。而且它的界面设计非常友好,即使是第一次接触的新手也能很快上手,快去试试吧!