Claude Opus 4.8 在标准模式下的费用为每百万 input tokens 5 美元,每百万 output tokens 25 美元。这与 Opus 4.7 的费率相同,因此如果您已经为 4.7 制定了预算,升级时无需更改。有趣的部分在于核心数字之外:更快的模式、token 消耗调节拨盘、caching 以及批量折扣,这些对实际账单的影响远超基础费率。
本指南将通过实际案例拆解您的实际支出。有关模型概览,请参阅什么是 Claude Opus 4.8。要开始构建,请参阅 API 指南。
费率表
| 模式 | 输入(每 1M tokens) | 输出(每 1M tokens) | 速度 |
|---|---|---|---|
| Standard | $5 | $25 | 基准 |
| Fast | $10 | $50 | 输出速度提升 2.5 倍 |
有两个重点值得注意。首先,output tokens 的成本是 input tokens 的五倍,因此 Claude 响应的长度决定了您的账单,而不是 prompt 的大小。其次,快速模式(fast mode)的费率翻倍,以换取快 2.5 倍的输出速度。Anthropic 指出,快速模式比之前模型的同等模式便宜约三倍,因此速度溢价已随代际更迭而下降。
您可以在 Anthropic 价格文档中确认当前费率。
快速模式的用途
标准模式(standard mode)是默认选项,也是大多数工作负载的正确选择。快速模式适用于“延迟即产品”的场景:实时编程助手、交互式智能体,以及任何用户正在盯着光标看的场景。您支付双倍的 token 费率,换取快 2.5 倍的流式输出。
决策很简单:如果有真人正在实时等待响应,快速模式是值得的。如果任务在后台运行(如智能体循环、批量作业、定时任务),请保持标准模式以节省资金。
Effort 参数如何改变您的账单
这是大多数团队忽略的杠杆。Opus 4.8 的 effort 参数控制模型在整个响应(包括 tool calls)中消耗的 token 数量。由于输出是昂贵的一半,在不需要深度推理的任务中降低 effort 可以直接削减成本。
按 token 消耗从低到高排列的五个级别:
low:简洁回答,最少的 tool calls,最低消耗medium:平衡high:默认,详尽xhigh:深度推理,更多 tool calls,推荐用于编程max:无约束,最高消耗
一个在 low effort 下运行的分类任务所使用的 output tokens 可能只有 high 模式下的十分之一。同样的模型,同样的费率,账单却只是零头。Anthropic 的 effort 指南涵盖了每个级别如何保持质量。核心结论是:根据任务匹配 effort,而不是在所有地方都支付 high 的费用。
成本案例计算
所有数据均使用标准定价(每百万 tokens 输入 $5,输出 $25)。这些仅为说明性示例,您的实际 token 计数会有所不同。
场景 1:聊天机器人单轮对话。 1,000 input tokens,500 output tokens。
- 输入:1,000 / 1,000,000 x $5 = $0.005
- 输出:500 / 1,000,000 x $25 = $0.0125
- 总计:每轮约 $0.018
在 low effort 下,输出会缩减,使每轮成本降至 1 美分以下。
场景 2:智能体编程任务。 50,000 input tokens 的代码库上下文,8,000 output tokens(使用 xhigh)。
- 输入:50,000 / 1,000,000 x $5 = $0.25
- 输出:8,000 / 1,000,000 x $25 = $0.20
- 总计:每个任务约 $0.45
如果这 50K 上下文在多次调用中重复,prompt caching 会将输入成本降至约 $0.025,使总成本降至约 $0.23。
场景 3:隔夜批量任务。 1,000,000 input tokens,200,000 output tokens,通过 Batch API 运行,享受 50% 折扣。
- 输入:1,000,000 / 1,000,000 x $5 x 0.5 = $2.50
- 输出:200,000 / 1,000,000 x $25 x 0.5 = $2.50
- 总计:整个批处理约 $5.00
如需与其他更便宜的模型进行对比,请参阅 Gemini 3.5 Flash 价格拆解和 Xiaomi MiMo v2.5 API 成本。
Prompt caching:最大的单项节省
如果您在每次调用时都发送相同的 system prompt、文档或代码库,那么您正在为模型已经见过的 tokens 支付全额输入价格。Prompt caching 解决了这个问题。在初始缓存写入后,缓存的输入读取费用仅为正常输入费率的一小部分(约为十分之一)。
长上下文智能体节省最多。每次调用都按全额计费的 50K token system prompt 非常昂贵;缓存后,重复部分的成本几乎为零。第一次调用写入缓存,之后的每次调用读取缓存都非常便宜。
Batch API 与超长输出
当您不需要实时答案时,Batch API 以折扣价运行任务。提交一组请求,在批处理窗口内获取结果,支付更低的每 token 费用。它还提高了输出上限:Opus 4.8 通过 Batch API 支持高达 300K 的 output tokens(需使用 output-300k-2026-03-24 beta header),而同步端点仅为 128K。
将其用于评估(evals)、批量摘要、数据标注以及任何对分钟级延迟不敏感的流水线。
Opus 历代价格对比
Opus 4.8 维持了价格水平。真正的故事是两代前价格下降的幅度:
| 模型 | 输入(每 1M) | 输出(每 1M) |
|---|---|---|
| Opus 4.1 | $15 | $75 |
| Opus 4.5 | $5 | $25 |
| Opus 4.6 | $5 | $25 |
| Opus 4.7 | $5 | $25 |
| Opus 4.8 | $5 | $25 |
Opus 在 4.5 世代从 $15/$75 降至 $5/$25,并一直保持至今,而价格背后的模型性能在不断提升。您正以 4.5 的费率获得 4.8 的质量。如需与其他厂商的旗舰模型进行对比,请参阅 Opus 4.8 vs GPT-5.5 vs Gemini 3.5。
成本优化清单
在规模化使用 Opus 4.8 之前,请对照此清单:
- 按任务设置 effort。 不要为分类任务支付
high费用,也不要为查找任务支付xhigh费用。 - 缓存重复上下文。 System prompts、文档和代码库都应该被缓存。
- 批量处理非紧急任务。 将评估和批量作业移至 Batch API。
- 合理限制
max_tokens。 它限制了单次调用最坏情况下的输出成本。 - 除非有真人实时等待,否则保持标准模式。
- 关注使用层级(usage tiers)。 速率限制和支出是同步增长的;Claude Code 每周限制增加 50% 的变动提醒我们要追踪配额。
使用 Apifox 追踪实际支出
一旦进入生产环境,预估成本和实际成本会迅速偏离,因为实际响应的长度和 tool-call 数量各不相同。保持透明的方法是检查每个 Messages API 响应返回的 usage 对象,它报告了每次调用的输入和输出 token 计数。
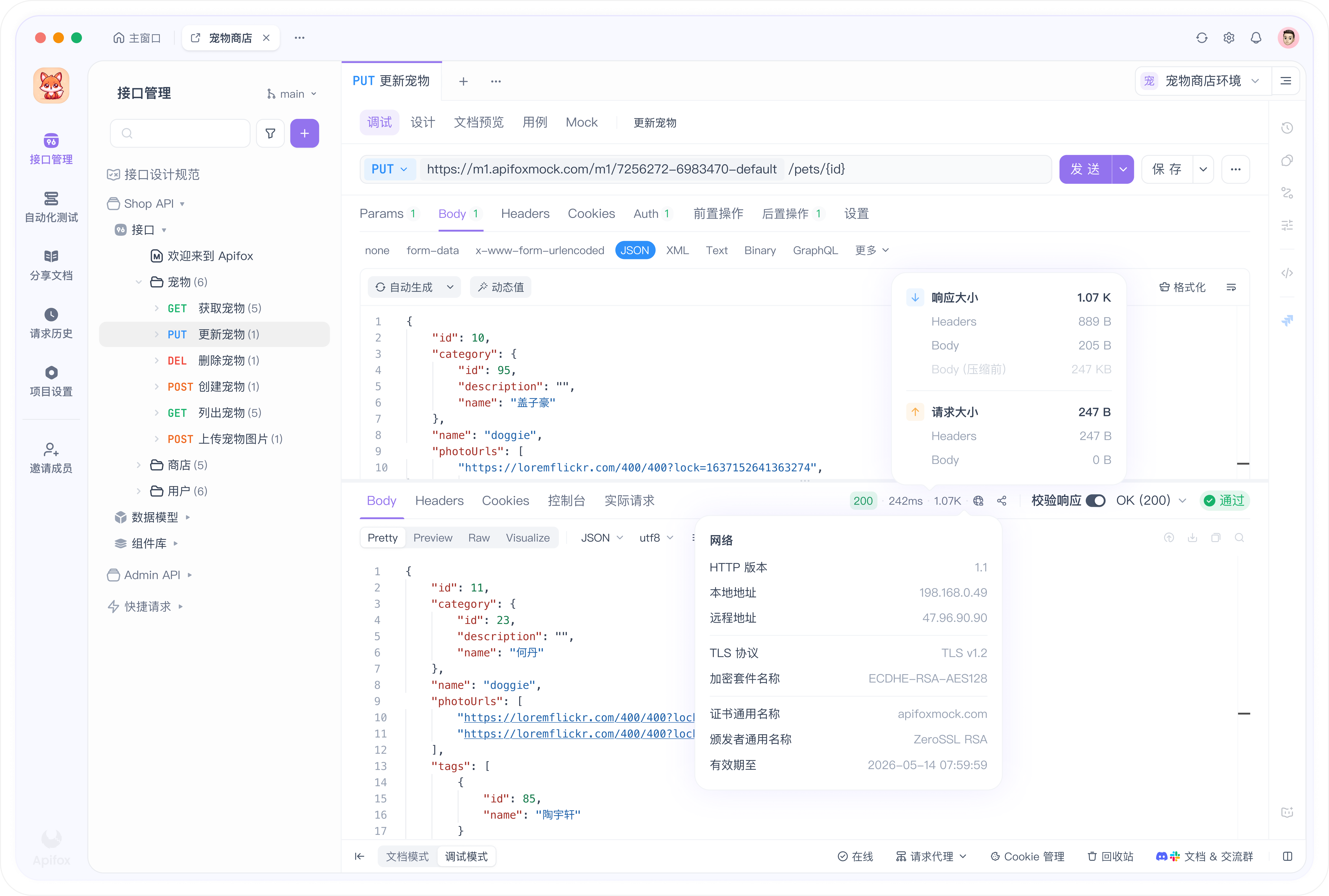
Apifox 使其可视化:
- 发送真实的 Opus 4.8 请求并读取响应中的
usage块。 - 在同一 prompt 上对比不同
effort级别的 token 计数,直接查看成本差异。 - 为每个工作负载保存请求,并在 prompt 更改时重新运行。
- Mock 端点,以便在不消耗 token 的情况下进行构建和测试。
下载 Apifox,将请求指向 Messages 端点,并以 low、high 和 xhigh 运行相同的 prompt。在投入生产环境之前,token 计数会准确告诉您每个 effort 级别的成本。
常见问题解答
Claude Opus 4.8 的费用是多少? 标准模式下每百万 input tokens 5 美元,每百万 output tokens 25 美元。快速模式为 10 美元和 50 美元,输出速度快 2.5 倍。
Opus 4.8 比 Opus 4.7 更贵吗? 不。每 token 费率完全相同,因此从 4.7 升级不会改变您的账单。
标准模式和快速模式定价有什么区别? 快速模式将每 token 费率翻倍,以换取快约 2.5 倍的流式输出。仅在延迟对等待用户至关重要时使用它。
如何降低 Opus 4.8 的成本? 在较简单的任务上降低 effort 级别,缓存重复的 prompt 内容,批量处理非紧急任务,并严格限制 max_tokens。Output tokens 是主要的成本驱动因素。
Prompt caching 真的能省钱吗? 是的。在第一次调用写入缓存后,重复输入的读取费用约为正常输入费率的十分之一。长上下文智能体节省最多。
Opus 4.8 可以产生多少个 output tokens? 同步 Messages API 高达 128K,通过 Batch API 使用 output-300k-2026-03-24 beta header 可达 300K。
在哪里可以查看每次调用的 token 使用情况? 在每个 Messages API 响应的 usage 对象中。像 Apifox 这样的工具可以将其呈现出来,以便您对比不同 effort 级别的成本。
开发必备:API 全流程管理神器 Apifox
介绍完上文的内容,我想额外介绍一个对开发者同样重要的效率工具 —— Apifox。作为一个集 API 文档、调试、设计、测试、Mock、自动化测试于一体的工具,Apifox 是目前提升研发效率的首选。
如果你正在开发项目,不妨试试其极其友好的界面设计,它完全兼容 Postman 和 Swagger 数据格式,导入数据非常方便,,即使是新手也能很快上手,点击这里即可注册使用。
值得一提的是,除了个人和常规团队使用,针对有高安全合规要求、或需要在内网环境协作的企业,Apifox 还提供了深度定制的私有化部署方案。
获取专属报价与部署方案
 详细的私有化部署系统架构与安全白皮书
详细的私有化部署系统架构与安全白皮书
 针对您公司规模的专属报价单
针对您公司规模的专属报价单
 免费的 1v1 专属产品演示 (Demo) 机会
免费的 1v1 专属产品演示 (Demo) 机会

