每次重启 Claude Code 都要重新解释一遍项目背景?跨会话的上下文丢失让你重复劳动?一个开源项目正在解决这个痛点。
claude-mem 为 Claude Code 构建了持久化记忆系统。它自动捕获工具使用记录,生成语义摘要,并在未来会话中提供这些上下文。这意味着 Claude 能在会话结束后依然保持对项目的连续性认知。
核心机制与工作原理
claude-mem 的运作流程清晰而高效。系统通过一系列生命周期钩子捕获开发活动,在后台异步处理并存储。
当新会话开始时,系统会自动注入最近的观察记录作为初始上下文。用户与 Claude 的每次交互、每个工具执行(如文件读写)都会被捕获为观察点。独立的 Worker 服务随后通过 Claude Agent SDK 从这些原始记录中提取“学习要点”。会话结束时,系统生成摘要,为下一次对话做好准备。
整个架构建立在几个关键组件之上:
| 组件 | 功能描述 |
|---|---|
| 5个生命周期钩子 | 覆盖会话开始、用户提交提示、工具使用后、停止、会话结束等关键节点 |
| Worker 服务 | 运行在端口 37777 上的 HTTP API,提供 Web 查看器界面和搜索端点 |
| SQLite 数据库 | 存储会话、观察记录和摘要,支持 FTS5 全文搜索 |
| Chroma 向量数据库 | 实现混合语义+关键词搜索,支持智能上下文检索 |
快速开始:五分钟内上手
安装过程极其简单。在 Claude Code 终端中开启新会话,执行以下命令:
> /plugin marketplace add thedotmack/claude-mem
> /plugin install claude-mem
重启 Claude Code 后,之前会话的上下文就会自动出现在新会话中。无需额外配置,系统开始透明地在后台工作。
安装完成后,可以立即访问本地 Web 查看器界面。在浏览器中打开 http://localhost:37777,实时查看记忆流、搜索历史记录,或调整系统设置。
智能搜索:自然语言查询项目历史
claude-mem 最强大的功能之一是 mem-search 技能。当你在对话中询问过去的工作时,Claude 会自动调用这个技能来查找相关上下文。
这种设计带来了显著的效率提升。相比传统的 MCP 方法,每个会话启动时大约能节省 2,250 个令牌。你可以用自然语言提问,系统理解你的意图并返回精确结果。
搜索系统支持多种查询维度:
| 搜索类型 | 查询示例 |
|---|---|
| 按概念标签 | “我们之前关于身份验证的决策是什么?” |
| 按文件引用 | “worker-service.ts 文件有哪些修改记录?” |
| 按观察类型 | “显示所有标记为 bugfix 的观察记录” |
| 时间线查询 | “添加查看器 UI 时发生了什么?” |
实际使用中,只需像平常一样提问:“上周我们如何解决那个性能问题的?”或“这个模块之前有过类似的重构吗?”。系统会自动理解并检索相关信息。
渐进式披露:优化上下文管理策略
claude-mem 采用分层记忆检索策略,模拟人类记忆的工作方式。这种设计在保持上下文完整性的同时,最小化令牌消耗。
第一层是索引层,在会话开始时显示存在哪些观察记录及其令牌成本。第二层是细节层,按需通过 MCP 搜索获取完整叙述。第三层是完美回忆层,访问源代码和原始记录。
系统为每个观察记录提供类型指示器,帮助快速识别重要性:
- 🔴 关键问题或阻塞项
- 🟤 重要决策点
- 🔵 一般信息性内容
这种设计让 Claude 能在获取详细信息和直接阅读代码之间做出智能选择,基于令牌成本进行优化决策。
配置与定制:按需调整系统行为
所有设置都通过 ~/.claude-mem/settings.json 文件管理。首次运行时系统会自动创建带默认值的配置文件。
关键配置项包括上下文观察数量、AI 模型选择和工作端口等。v6.4.9 版本引入了细粒度控制,提供 11 个新设置项,允许精确调整上下文注入策略。
通过命令行工具可以方便地管理设置:
# 使用 CLI 助手编辑设置
./claude-mem-settings.sh
# 或直接编辑配置文件
nano ~/.claude-mem/settings.json
# 查看当前设置
curl http://localhost:37777/api/settings
隐私控制是另一个重要特性。双标签系统允许用户用 <private> 标签包裹敏感内容,确保这些信息永远不会进入数据库。系统级的 <claude-mem-context> 标签则防止观察记录的递归存储。
测试版功能:无尽模式探索
claude-mem 提供测试版通道,包含实验性功能。通过 Web 查看器界面可以直接在稳定版和测试版之间切换,无需手动 Git 操作。
无尽模式是旗舰测试功能,采用仿生记忆架构显著延长会话长度。标准 Claude Code 会话在使用约 50 个工具后会达到上下文限制,每个工具添加 1-10k+ 令牌,Claude 每次响应时重新合成所有先前输出(O(N²) 复杂度)。
无尽模式将工具输出压缩到约 500 个令牌的观察记录中,并实时转换记录:
| 内存类型 | 内容 | 大小 |
|---|---|---|
| 工作内存(上下文) | 压缩的观察记录 | ~500 令牌每个 |
| 存档内存(磁盘) | 完整的工具输出 | 完整保存供回忆 |
这种设计带来显著改进:上下文窗口减少约 95% 的令牌使用,工具使用次数增加约 20 倍才达到上下文耗尽,复杂度从二次 O(N²) 降至线性 O(N)。完整记录仍被保存以供完美回忆。
需要注意的是,该功能会增加延迟(每个工具观察生成需要 60-90 秒),目前仍处于实验阶段。
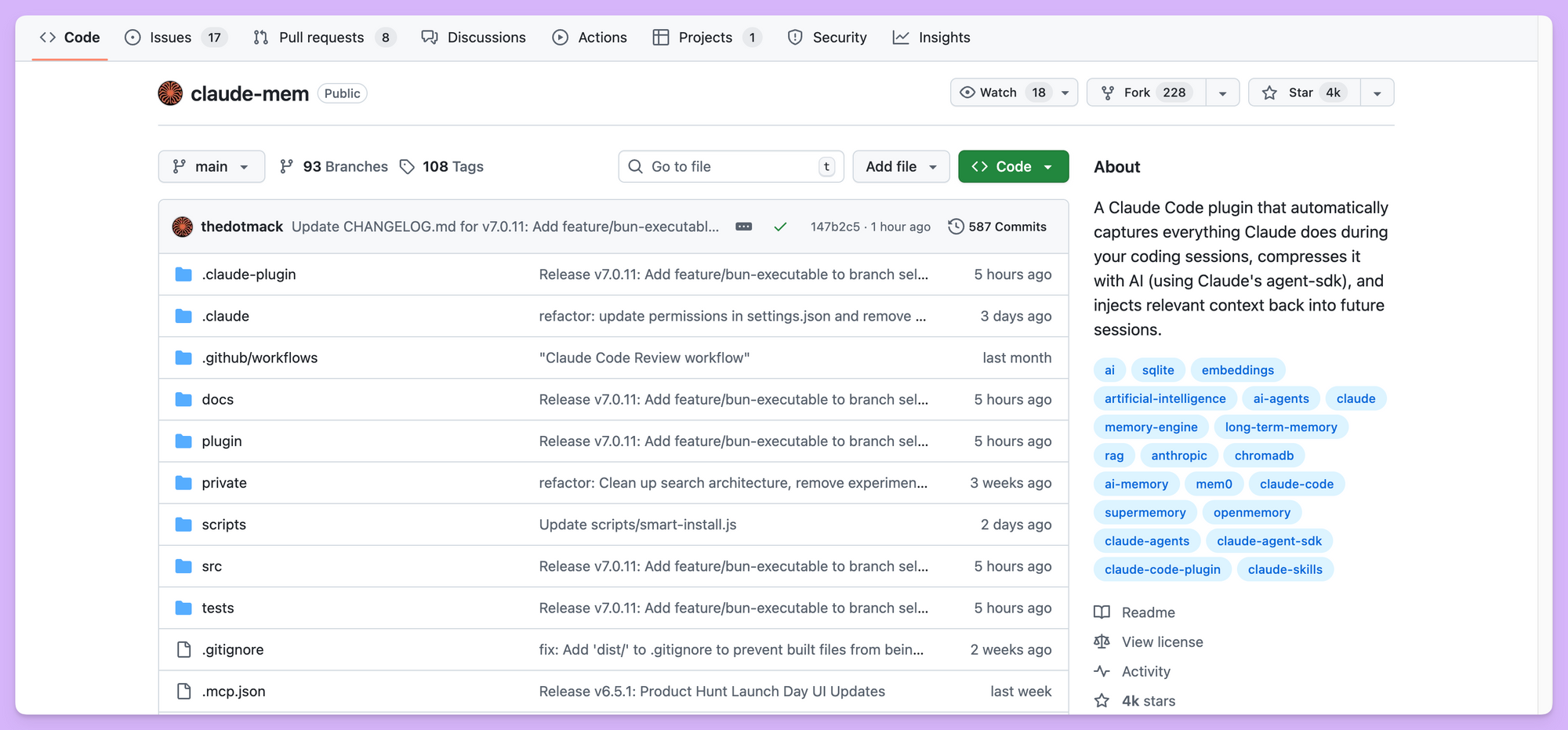
开发与贡献指南
对于想要深入了解或贡献代码的开发者,项目提供了完整的开发环境设置指南。
克隆仓库后,标准的 Node.js 工作流即可开始:
git clone https://github.com/thedotmack/claude-mem.git
cd claude-mem
npm install
npm run build
# 运行测试套件
npm test
# 启动 Worker 服务
npm run worker:start
# 查看实时日志
npm run worker:logs
项目采用模块化架构,核心逻辑分布在多个目录中。数据库层使用 SQLite 配合 FTS5 扩展,搜索层整合 Chroma 向量数据库,前端查看器基于现代 Web 技术构建。
贡献流程遵循标准开源实践:Fork 仓库、创建特性分支、进行更改并添加测试、更新文档,最后提交 Pull Request。项目维护者积极 review 社区贡献,特别是错误修复、性能改进和新功能提案。
故障排除与支持
遇到问题时,系统内置了诊断工具。只需向 Claude 描述问题,故障排除技能会自动激活,诊断并提供修复方案。
常见问题有标准解决方案。Worker 服务未启动时可以运行 npm run worker:restart。上下文未出现时使用 npm run test:context 检查。数据库问题可以通过 SQLite 的完整性检查命令诊断。
项目文档提供了完整的故障排除指南,覆盖从安装问题到搜索故障的各个方面。社区在 GitHub Issues 中活跃讨论,维护者通常能在几天内响应问题报告。
持久化记忆改变了开发者与 AI 编码助手的协作方式。不再需要每次会话都重新建立上下文,不再担心重要的技术决策在重启后丢失。claude-mem 让 Claude Code 真正成为理解项目历史、延续思考过程的智能伙伴。
开发必备:API 全流程管理神器 Apifox
介绍完上文的内容,我想额外介绍一个对开发者同样重要的效率工具 —— Apifox。作为一个集 API 文档、API 调试、API 设计、API 测试、API Mock、自动化测试等功能于一体的 API 管理工具,Apifox 可以说是开发者提升效率的必备工具之一。
如果你正在开发项目需要进行接口调试,不妨试试 Apifox。注册过程非常简单,你可以直接在这里注册使用。
注册成功后可以先看看官方提供的示例项目,这些案例都是经过精心设计的,能帮助你快速了解 Apifox 的主要功能。
使用 Apifox 的一大优势是它完全兼容 Postman 和 Swagger 数据格式,如果你之前使用过这些工具,数据导入会非常方便。而且它的界面设计非常友好,即使是第一次接触的新手也能很快上手,快去试试吧!