




如何在 Apifox 中快速构建和调试 AI Agent


如果你正在开发 AI Agent,应该很容易遇到这类问题:
- 怎么快速把模型、提示词(Prompt)、工具和 MCP 能力组合成一个可运行的 Agent?
- Agent 运行后,怎么确认模型有没有按预期调用工具?
- 明明 MCP Server 已经接好了,为什么没有按预期继续执行?为什么传错了参数?
- 换了一个模型之后,效果好像变好了,但耗时、词元(Token) 和成本到底有没有增加?
过去我们调试 AI 应用时,往往只能看到两端:用户输入了什么,模型最终输出了什么。
随着应用从传统接口逐步扩展到 MCP 和 Agent,开发者需要调试的不再只是接口请求和响应,还包括模型决策、工具调用和外部能力的协同过程。
但对 Agent 来说,真正影响结果的,往往不只是最后那段回答,而是中间完整的执行过程:模型每一轮是怎么思考的、调用了哪些工具、参数传得对不对、工具返回了什么、有没有报错、最后又是如何生成答案的,这些信息如果看不见,调试就很容易变成反复猜测。
所以,Apifox 新增了 AI Agent Debugger,帮助开发者在一个界面中完成 Agent 的配置、运行、观察和迭代,让 AI Agent 从搭建到调试都更直观。
AI Agent Debugger 是什么
AI Agent Debugger 是面向 AI Agent 开发者的构建和调试工具,可以配置模型、提示词、工具、MCP Server、技能(Skill)、认证信息和模型参数,快速搭建一个可运行的 Agent,并在运行后查看完整的执行过程。
也就是说,它不只是用来查看运行结果,而是把 Agent 的配置、运行和调试放在同一个流程中完成。
如果你正在开发或调试 AI Agent,它可以帮你更快验证配置是否符合预期,并观察每次运行中的真实执行过程。
为什么需要 Agent 构建和调试工具
过去的软件调试更多面对的是确定性的代码和接口:输入是什么、输出是否符合预期,通常可以通过测试和断言来判断。
但 AI Agent 不同。一次 Agent 任务的结果,往往由模型、提示词、工具、MCP Server 和上下文共同决定。即使输入相同,不同模型、参数或工具状态,也可能带来不同的执行路径。
因此,Agent 调试不能只看最终结果是否正确,更要评估整个执行过程是否合理:模型是否理解了任务,是否选择了正确工具,参数是否传对,工具返回是否正常,耗时和成本是否可控。
这些问题如果没有完整链路,很难排查。AI Agent Debugger 的作用,就是把 Agent 的配置、运行和执行过程放到同一个调试流里,让你既能快速搭建一个可运行的 Agent,也能在每次运行后评估它的执行是否符合预期。
配置一个可运行的 Agent
在 AI Agent Debugger 中,构建一个 Agent 的第一步,是选择模型服务商和具体模型,并配置系统提示词和用户提示词。
对于 Agent 构建来说,提示词是最核心的配置之一。系统提示词用于定义 Agent 的角色、目标、约束和工具使用规则,用户提示词则是本次测试输入。很多工具没有被调用、调用时机不对、输出格式不稳定的问题,最后往往都能回到提示词配置中找到原因。
除了提示词,AI Agent Debugger 还可以配置本次运行开放给 Agent 的能力,包括内置工具、MCP 工具和技能。
- 内置工具可以让模型读取文件、获取网页内容、搜索文件、执行命令或修改内容
- MCP 工具用于接入外部系统或自定义能力,支持 STDIO、HTTP 和 SSE 等连接方式,也可以配置 Header 或 OAuth 2.0 完成鉴权
- 技能 更适合沉淀固定流程,例如读取项目上下文、运行测试、分析结果或遵循团队内部规范
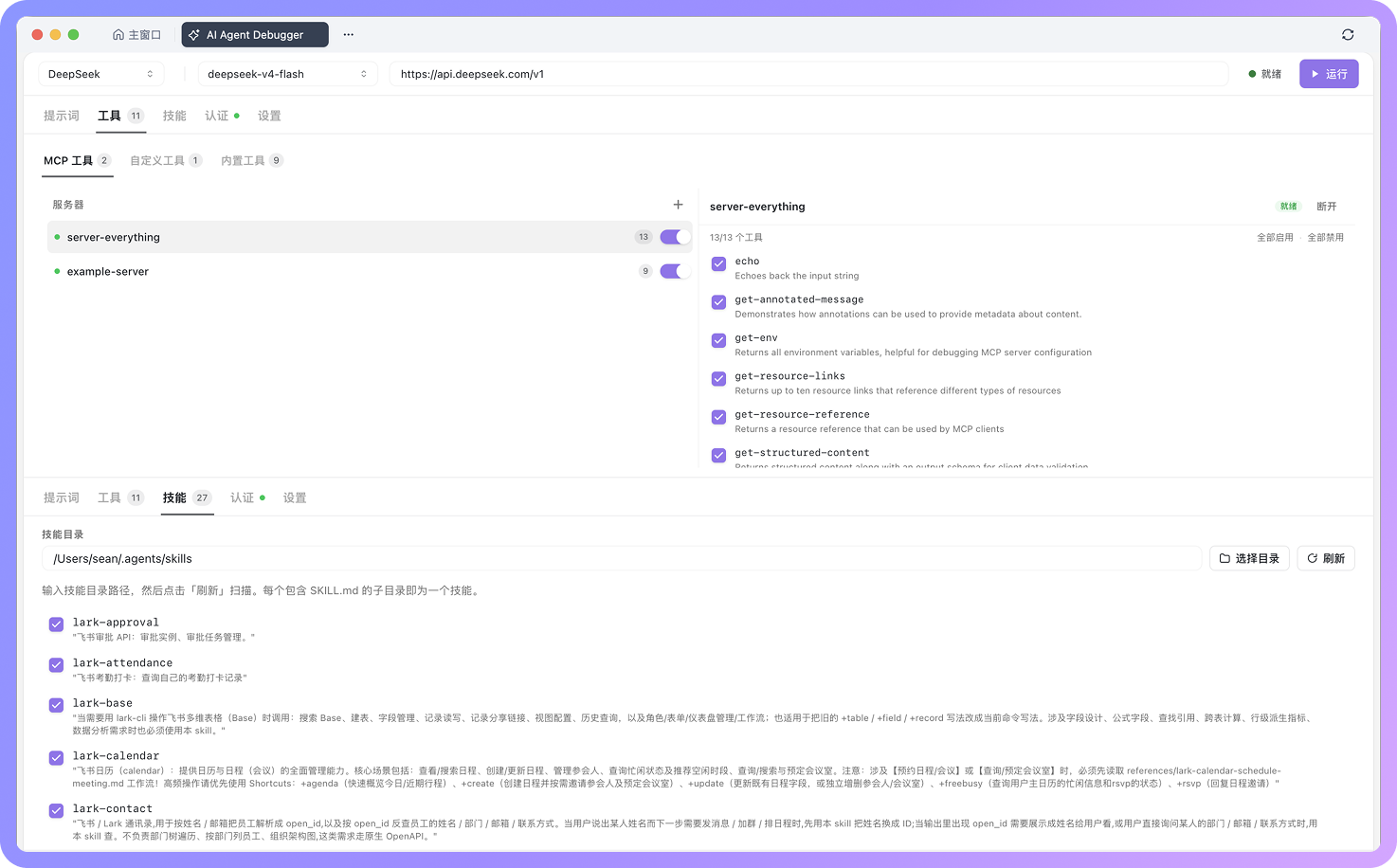
通过这些配置,你可以明确控制 Agent 在本次运行中「能调用什么」以及「应该怎么做」。如果后续工具调用失败,也可以结合调用追踪继续判断问题是出在提示词、模型选择、工具传参、MCP 连接,还是鉴权配置上。
在「认证」和「设置」中,还可以配置模型服务或 MCP 服务所需的认证信息,以及 Temperature、Max Tokens(最大词元数)、Top P 等模型参数。你可以保持提示词和工具不变,只切换模型或调整参数,再观察执行路径、耗时、词元消耗和最终输出是否发生变化。
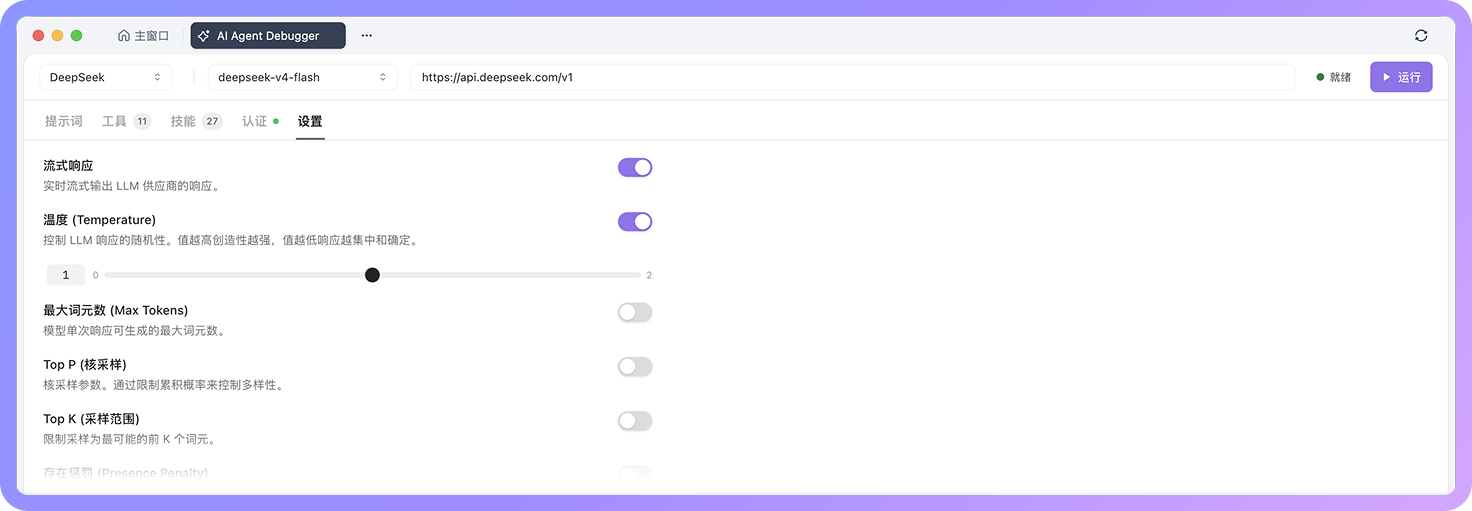
这样一来,一个典型的 Agent 构建和调试流程就可以串起来:配置 Agent、运行任务、观察调用追踪、根据结果调整提示词 或工具配置,再通过多次运行对比改动效果。
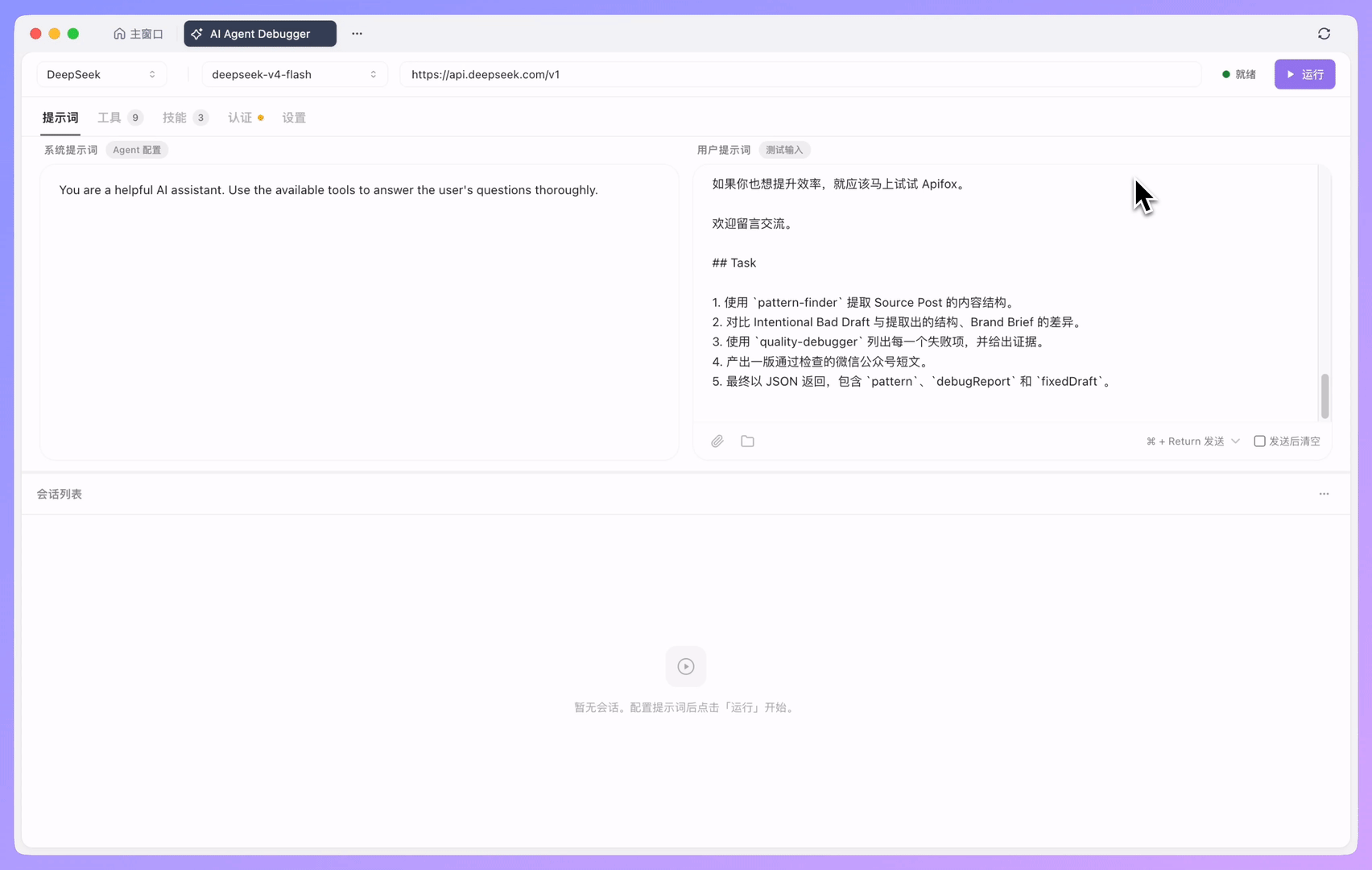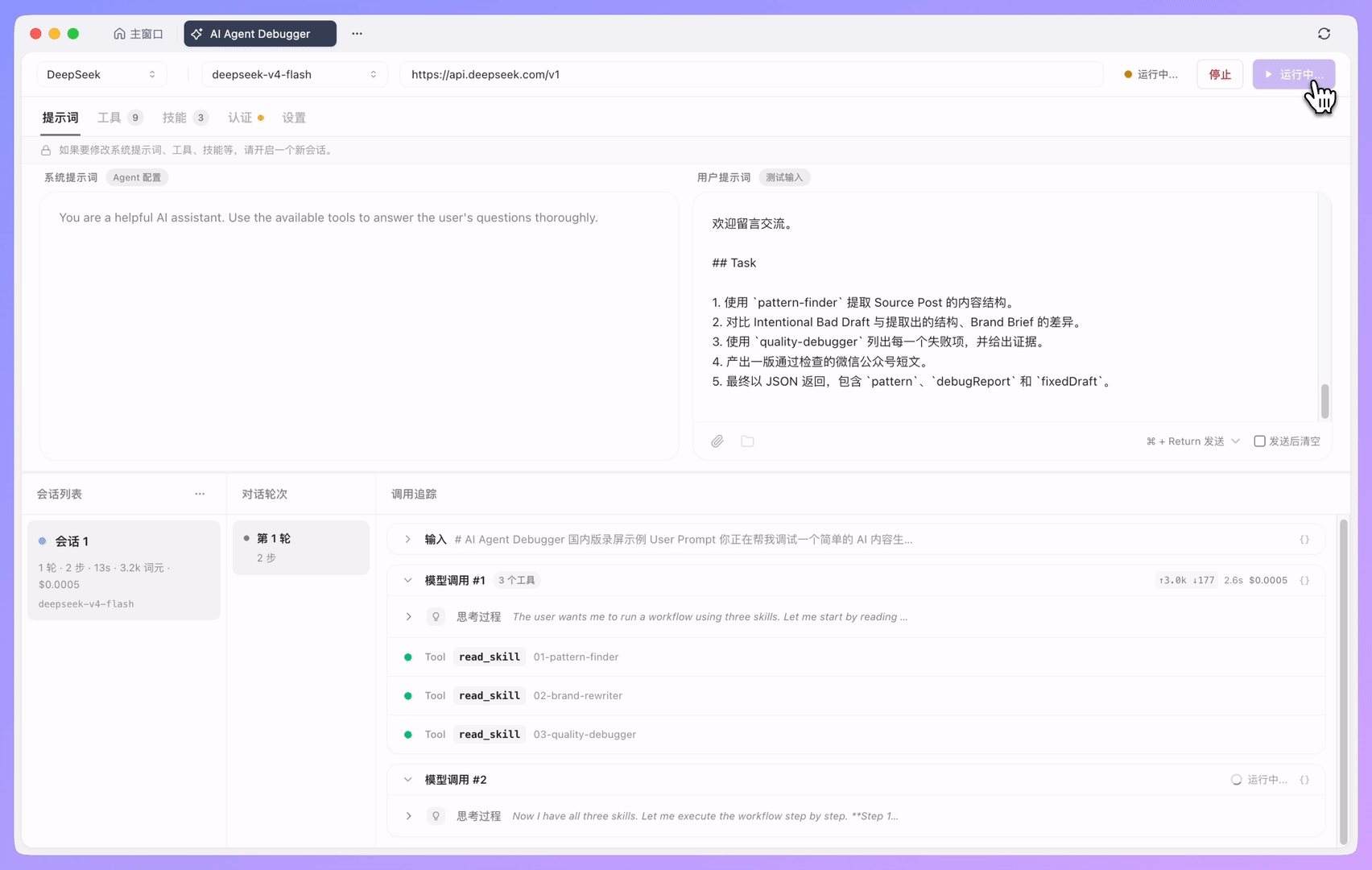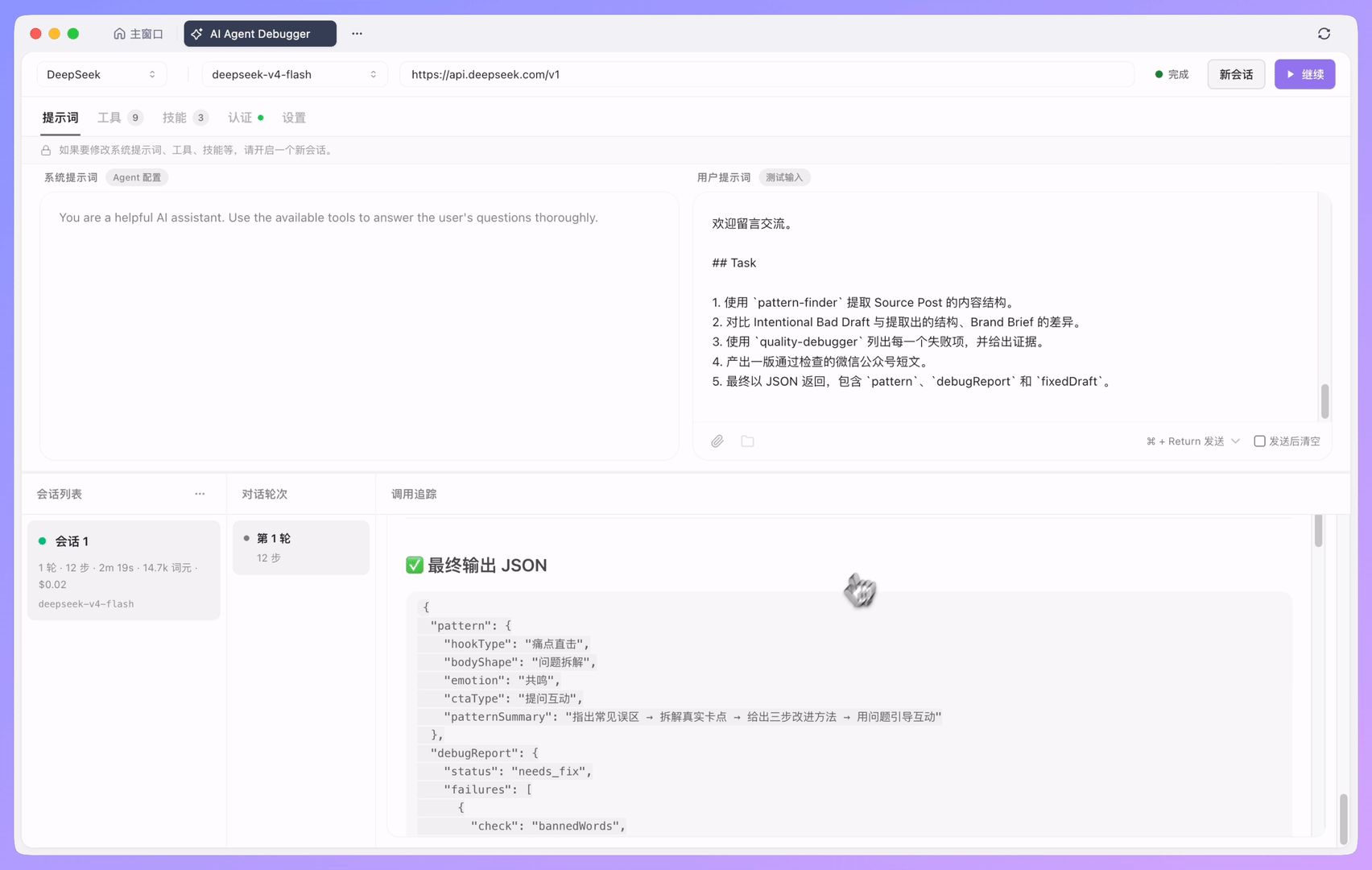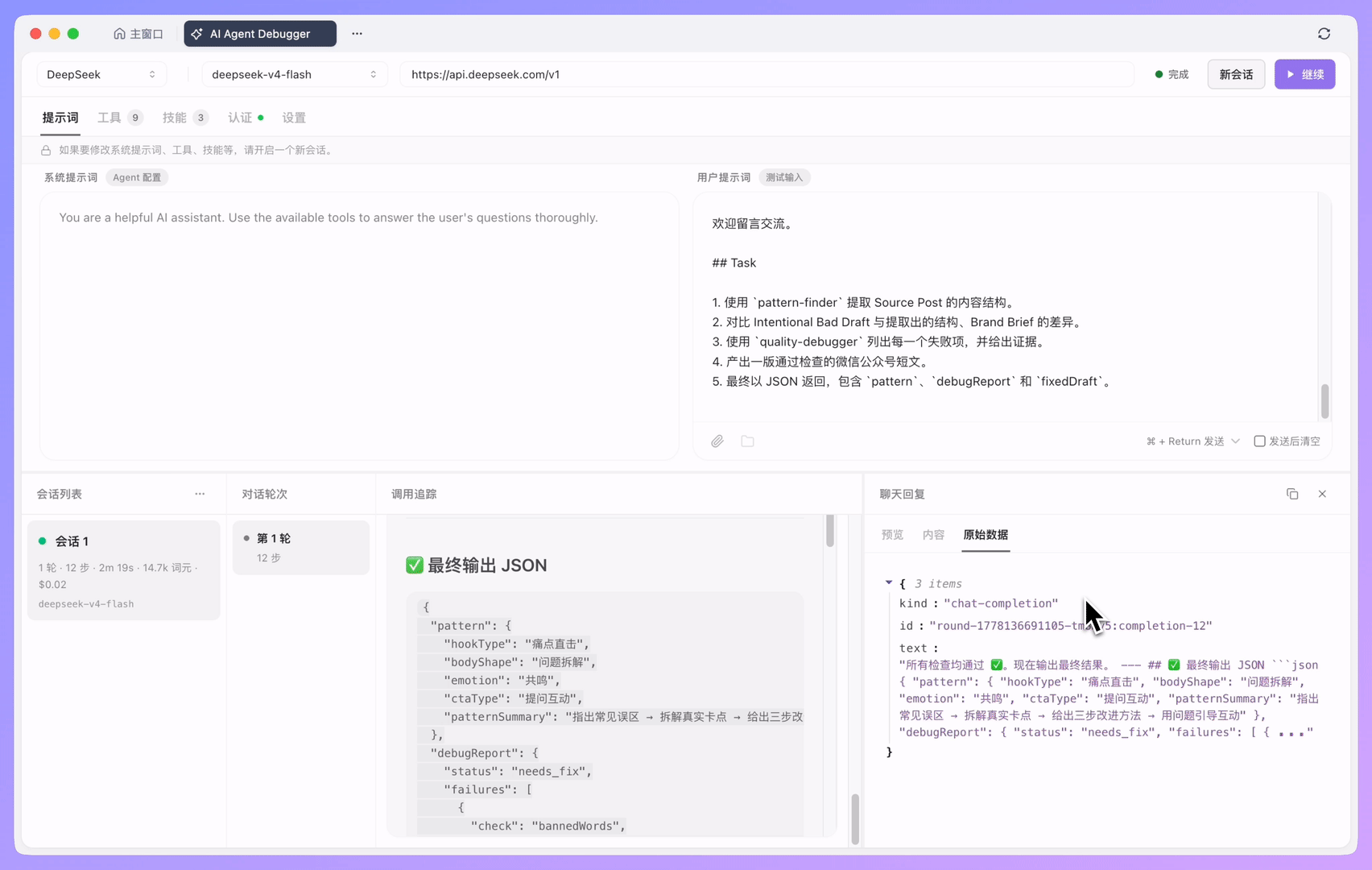
运行 Agent 并查看执行过程
每次运行都会生成一条会话记录。你可以在其中查看本次 Agent 执行过程中的关键信息,包括模型调用、工具调用、MCP 执行、技能读取、工具输入参数、执行结果、耗时、错误信息、词元消耗、预估成本和模型最终输出。
这些信息会按不同层级组织:先通过「会话记录」了解整体表现,再通过「对话轮次」定位具体上下文,最后进入「调用追踪」查看每一步执行细节。
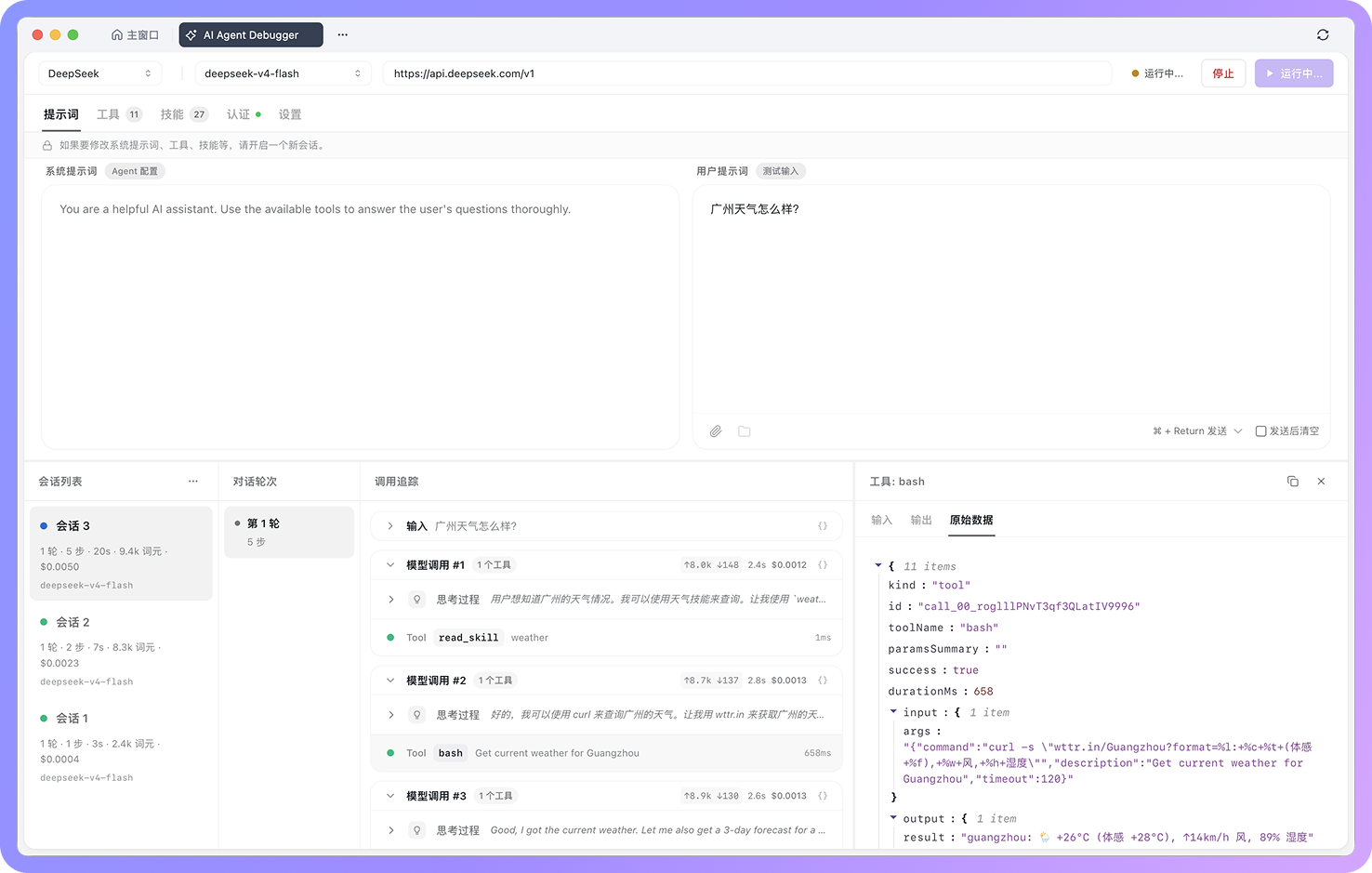
查看会话记录
每次运行后,左侧都会生成一条新的会话记录。会话列表会展示本次运行的整体摘要,例如对话轮数、执行步数、响应耗时、Token 消耗、预估成本和使用的模型。每条会话记录都会保留当时的模型、提示词、工具和参数配置,方便你回溯这次结果是在什么配置下产生的。
**会话 1**
1 轮 · 8 步 · 17s · 22.3k 词元 · $0.05 deepseek-v4-flash
通过会话列表,你可以先快速判断这次运行的整体表现,再决定是否继续展开对话轮次和调用追踪查看细节。
查看对话轮次
中间的「对话轮次 」面板,会展示当前会话中的多轮对话。如果一次会话包含多轮用户输入,每一轮都会单独展示。点击某一轮后,右侧会显示这一轮对应的调用过程。
这对排查多轮 Agent 很有帮助。因为很多问题并不是出现在第一轮,而是随着上下文不断累积,模型在某一轮开始偏离预期。通过对话轮次拆开查看,可以更快定位是哪一轮开始出现异常。
查看调用追踪
右侧的「调用追踪 」是 AI Agent Debugger 中最重要的调试区域,它会按照执行顺序展示本次 Agent 运行中的每一个关键步骤。
当模型调用工具时,你可以看到工具名称、输入参数、执行结果、耗时以及错误信息。当模型返回最终结果时,也可以回到前面的步骤,检查这个结果是基于哪些上下文和工具返回生成的。
比如 MCP 工具没有返回预期结果时,不需要再反复猜测。你可以直接看:
- 模型有没有调用工具
- 调用的是不是目标工具
- 传入参数是否符合工具要求
- 工具返回是否正常
- 错误发生在模型调用前,还是工具执行后
这些信息连起来之后,问题通常就能定位到具体环节。
通过多次运行迭代 Agent 效果
构建 Agent 往往不是一次配置就完成的。你可以保持任务不变,调整模型、提示词、工具或技能配置,然后通过多次运行观察执行路径、响应耗时、词元消耗和最终输出的变化。
如果你想对比不同模型,也可以保持提示词、工具和技能配置不变,只切换不同模型运行同一个任务,然后观察会话列表和调用追踪中的差异。
除了最终回答是否符合预期,还可以重点关注:
同一任务在不同模型下的执行步数是否不同
哪个模型能更准确地选择工具
哪个模型的响应耗时更低
哪个模型的词元消耗和成本更可控
对于 AI Agent 来说,模型选择并不只是「回答好不好」的问题。一个模型可能回答质量不错,但工具调用链路更长、Token 消耗更高、成本也更高。
通过 AI Agent Debugger,你可以把这些因素放在一起看,更容易找到效果、性能和成本之间的平衡点。
常见使用场景
基于完整的会话记录和调用追踪,AI Agent Debugger 适合用在这些场景中:
- 快速组合模型、提示词、工具、MCP Server 和技能,搭建可运行的 Agent
- 配置和优化提示词,让 Agent 按预期理解任务并选择工具
- 排查工具或 MCP 调用失败,检查参数、返回内容和错误信息
- 对比不同模型、提示词或工具配置下的调用路径、耗时和成本
- 观察多轮对话中上下文从哪一轮开始偏离
- 分析一次 Agent 任务为什么变慢、变贵或变得不稳定
总结
AI Agent Debugger 的核心价值,是把 AI Agent 的配置、运行、观察和迭代放到同一个流程里,让开发者可以更快搭建一个可运行、可调试、可持续优化的 Agent。
无论是组合模型、提示词、MCP 工具和技能 ,还是排查工具调用失败、对比不同模型效果,都可以在同一个界面中完成。
如果你正在构建 Agent、接入 MCP,或者评估不同模型在工具调用场景下的表现,可以用 AI Agent Debugger 跑一次真实任务,从配置到执行过程一起检查和优化。
如果在使用过程中遇到不太清楚的地方,也可以查看Apifox 帮助文档,里面有更完整的功能说明和配置示例。有任何问题欢迎在Apifox 用户群与我们交流沟通。
同时,Apifox 提供企业私有化部署版本,通过本地化部署、客制化服务,协助企业进一步提升研发团队效能。
