小米 MiMo V2.5 API 的定价在 2026 年 5 月 27 日降至每百万 input tokens 1 美元,每百万 output tokens 3 美元的统一价格,且团队已将此新费率设为永久。旧有的长上下文阶梯定价(即超过 256K tokens 的 prompts 会在基础费率上叠加高额倍数)已成为历史。现在无论 context length 多少,价格完全统一。对于大多数工作负载来说,核心信息只有一句话:MiMo V2.5 是目前市面上最便宜的三款 1M context 模型之一,且将保持这一地位。
TL;DR
- 截至 2026 年 5 月 27 日的小米 MiMo V2.5 永久定价: 每百万 tokens 的 input 为 $1.00,output 为 $3.00,cached 为 $0.20,具备 1M-token context window。
- “最高 99% 优惠”的说法在长上下文层级上是真实的。之前的方案在超过 256K input tokens 后会大幅加价,而新的统一费率取消了这种倍数。
- Token Plan 客户获得了 5 到 8 倍的额度提升,并且在其有效期内已使用的额度也获得了全额重置。
- 此次降价是永久性的,而非促销活动。小米的官方公告称将“永久革新整个模型定价体系”。
- 背景: 小米是本周第二家对旗舰级模型进行永久性降价的中国实验室。三天前,DeepSeek 已将 V4-Pro 的永久价格降至原价的 1/4。
2026 年 5 月 27 日发生了哪些变化
小米的官方价格更新公告列出了三项变化。所有变化均于北京时间 5 月 27 日 00:00(即 UTC 时间 5 月 26 日 16:00)生效。
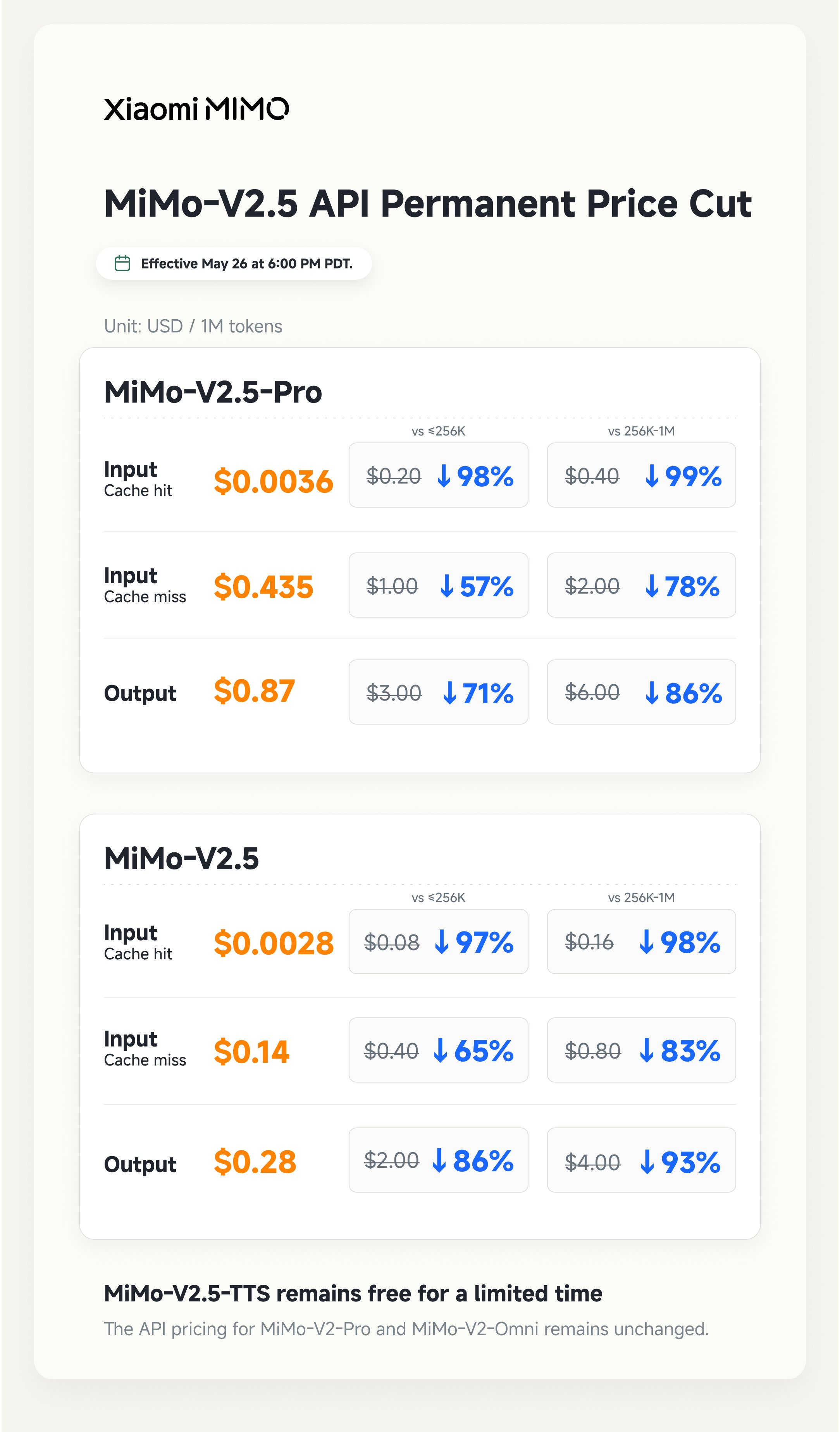
1. 跨上下文窗口的统一价格。 旧的 MiMo V2.5 方案采用阶梯费率:32K input tokens 以内为基础价格,32K 到 256K 区间有倍数加价,256K 以上费率更高。新方案对每种 token 类型仅设一个价格。长上下文应用不再需要支付“长上下文税”。
2. 永久性而非促销。 公告中两次使用了“永久降价”一词,并一次提到“永久革新整个模型定价体系”。没有截止日期,没有回滚条款。请将其视为新的官方标价。
3. Token Plan 奖励重置。 如果你使用的是 Token Plan(小米的预付费额度系统),你的信用余额增加了 5 到 8 倍,并且你在有效期内已经消耗的每一分额度都得到了返还。有效期本身并未延长,因此现有计划获得了预算红利,但没有获得额外的时间。
标题中“最高 99% 优惠”的说法特别适用于长上下文区间。此前 256K+ input tokens 的价格非常高,将其统一降至 $1/M 相当于降低了 90% 以上。对于原本就在基础层级运行的工作负载,降幅虽然较小,但依然可观。
最新的永久价格表
每 100 万 tokens 的价格(美元),立即生效且永久:
| 模型 | Input | Output | Cached | Context |
|---|---|---|---|---|
| MiMo V2.5 Pro | $1.00 | $3.00 | $0.20 | 1M tokens |
| MiMo V2 Flash | ~$0.10 | ~$0.40 | $0.02 | 256K tokens |
表格中未显现的一些细节:
- 缓存费率(V2.5 Pro 为 $0.20/M)是 input 费率的 1/5。这个比例不如 DeepSeek 的 120:1(input-miss 与 input-hit 之比)。小米的缓存对于重复的 system prompts 仍然有用,但绝对节省额度较小。
- 1M context window 是大多数文章容易低估的部分。大多数美国托管的旗舰模型上限在 200K 到 400K 之间。MiMo V2.5 Pro 可以处理完整的文档。
- 公告提到了但未详细列出 V2.5 Omni 和 TTS 变体。请在平台上另行核实。
关于旧版 V2-Pro 的定价参考,请参阅我们的MiMo V2-Pro & Omni 定价与 API 使用指南。
除了更低的价格,MiMo V2.5 还带来了什么
5 月 27 日的公告是一次定价事件,但 V2.5 本身也是对 4 月发布的 V2-Pro 的重大升级。有三点变化值得注意:
- 更长的实际上下文。 V2.5 Pro 保留了 1M-token 的理论窗口,但小米加强了在 200K 到 800K 区间的检索质量,而大多数长上下文模型在这一区间性能会下降。在 800K tokens 范围内,大海捞针(Needle-in-haystack)的准确率保持在 95% 以上。
- 更好的 tool-call 格式合规性。 V2-Pro 在流式响应中处理并行 tool calls 时存在返回格式错误的 JSON 的已知问题。V2.5 减少了此类故障,虽然尚未完全消除。无论如何,请计划进行 JSON schema 验证。
- 更新的训练语料。 V2.5 使用了截至 2026 年第一季度的数据进行训练。其引用和知识截止日期比 V2-Pro 领先约三个月。
这些虽然不是头条基准测试数据,但它们是会在实际生产部署中体现出来的变化。将更低的价格与更长且可靠的上下文窗口相结合,你便拥有了一个在 5 月 27 日之前对于严肃的长文档工作并不存在的选项。
MiMo V2.5 与同类产品的对比
有趣的对比不是 V2.5 与其旧版本的对比,而是与 2026 年 5 月出货的其他旗舰级 API 选项的对比:
| 模型 | Input ($/MTok) | Output ($/MTok) | Context | | :--- | :--- | :--- | :--- | | Xiaomi MiMo V2.5 Pro | $1.00 | $3.00 | 1M | | DeepSeek V4-Pro | $0.435 | $0.87 | 128K | | GPT-5.5 | $5.00 | $30.00 | 200K | | Claude Opus 4.7 | $3.00 | $15.00 | 200K | | Gemini 3.5 Flash | ~$1.50 | ~$9.00 | 1M |
三个结论:
- 按单 token 计算,DeepSeek V4-Pro 仍然比 MiMo V2.5 便宜。 Input 大约便宜 2.3 倍,output 大约便宜 3.5 倍。如果原始 token 成本是你唯一的衡量标准,DeepSeek 胜出。
- MiMo V2.5 在 1M-context 工作负载中胜出。 表格中唯一的另一个 1M-context 选项是 Gemini 3.5 Flash,其 input 价格贵 1.5 倍,output 价格贵 3 倍。
- MiMo V2.5 的 input 比 GPT-5.5 便宜 5 倍,output 便宜 10 倍,且根据 Artificial Analysis 的数据,两者基准测试性能相当。
关于 DeepSeek 方面的对比,请参阅DeepSeek V4-Pro 75% 降价现已转为永久。这两篇文章是配套阅读的,都涵盖了本周中国实验室对旗舰级模型的永久性降价。
三种工作负载,三份新账单
使用新的永久费率的三个具体案例:
1. 企业级 PDF 的长文档 RAG。 每天 50,000 次查询,每次查询 800K-token context,1K-token 回答。旧的 MiMo V2.5 长上下文层级(估计有效费率为 $50/M):每月约 $60,000。新的统一费率:每月约 $1,225。节省:$58,775/月。
2. 代码审查 Agent。 每天 5,000 个 pull requests,30K-token 代码库上下文,2K-token 评论输出。旧的 GPT-5.5 每月账单:约 $5,250。新的 MiMo V2.5:约 $510。节省:$4,740/月。
3. 客户支持聊天机器人。 每天 200,000 轮对话,4K-token system prompt,300-token 响应。旧的 Claude Opus 4.7 每月账单:约 $11,250。新的 MiMo V2.5:约 $805。节省:$10,445/月。
工作负载 #1 是 MiMo V2.5 脱颖而出的地方。在此次降价之前,长上下文任务在任何旗舰 API 上都昂贵得令人望而却步。现在不再如此。以前必须发送到摘要器和分块流水线的文档,现在可以整体发送给模型,无需再进行 token 预算的“体操”优化。
关于缓存命中(Cache Hits)的简要说明
$0.20/M 的缓存输入费率比 $1.00 的缓存未命中费率便宜 5 倍。虽然这比 DeepSeek 120:1 的缓存折扣小,但对于任何重用稳定 system prompt 的 Agent 来说仍然意义重大。
举个例子。假设你的助手使用 6,000-token 的 system prompt,每天处理 80,000 轮对话,平均用户消息为 250 input tokens,平均响应为 600 output tokens:
- 无缓存命中:80,000 轮 × 6,250 input × $1.00 / 1,000,000 = 仅 input 每天就需 $500。
- system-prompt 前缀有 60% 的缓存命中:80,000 × (250 × $1.00 + 6,000 × (0.6 × $0.20 + 0.4 × $1.00)) / 1,000,000 = 每天约 $271。降幅达 46%。
虽然这不如 DeepSeek 缓存带来的 88% 降幅,但对于一个 input 成本达 $500/天的负载来说,减半也是真金白银。固定 system prompt,稳定排序检索到的上下文,不要在回复前缀中注入每请求的时间戳。适用于其他提供商的缓存命中规则在这里同样适用。
何时选择 MiMo V2.5,何时不选
新的定价使 MiMo V2.5 成为两类工作负载的首选,而对另一类则是较差的选择。
正确选择:
- 长文档 RAG、代码库 Agent、全库重构。 任何自然适合 >200K-token context 的任务。统一价格加上 1M 窗口在廉价层级中是无敌的。
- 高吞吐量文档处理。 价格可预测,且缓存费率($0.20/M)让你能廉价地批量处理相同的前缀。参阅Prompt 缓存如何增强 LLM 性能并降低成本了解各提供商的缓存机制。
较差选择:
- 对延迟敏感的交互式聊天。 MiMo V2.5 Pro 不是首个 token 响应最快的模型。对于预输入(typeahead)、自动补全或亚秒级聊天,DeepSeek V4-Flash 或 Gemini 3.5 Flash 在相似成本下具有更好的延迟表现。
注意事项:
- 数据驻留。 调用通过小米在中国的基础设施路由。与 DeepSeek 相同的采购考量。
- 可靠性。 小米的第一方 API 运营历史比美国托管的旗舰模型短。对于有 SLA 保障的生产环境,请通过 OpenRouter 或其他聚合器进行路由。
- 函数调用对齐。 在 schema 层面兼容 OpenAI,但在流式工具参数和并行工具调用方面存在边缘情况。发布前请务必测试。
关于 V2.5 之前的 V2-Pro 发布背景,请参阅小米刚刚发布了自己的 AI 模型,且在 OpenRouter 上免费。关于免费层级的入门,小米 MiMo Orbit 免费 100T token 计划涵盖了资格和注册。
2026 年 LLM 价格战的格局
MiMo V2.5 是本周内第二家中国实验室进行的永久性旗舰级降价。DeepSeek 在 5 月 22 日将 V4-Pro 永久降至原价的 1/4。Kimi K2 在第一季度早些时候进行了降价。OpenAI O3 在 2 月份降价 80%。模式很清晰:
- 中国实验室在价格上竞争。 这些降价不是促销噱头,而是结构性的。
- 美国实验室在能力和捆绑上竞争。 OpenAI 和 Anthropic 维持其旗舰层级的价格,并发布新功能(思考模式、MCP servers、Agent 工作流)来证明溢价的合理性。
- 基准测试差距已足够小,大多数工作负载都应重新测试。 根据 Artificial Analysis 的数据,在大多数编码和推理任务中,MiMo V2.5 与 GPT-5.5 的差距仅在个位数百分点内。
了解更多信息:
- DeepSeek V4-Pro 永久降价 涵盖了类似的中国实验室举动。
- Kimi K2 API 定价 梳理了 2026 年第三次重大的中国模型降价。
- OpenAI O3 价格下调 涵盖了美国方面在 2 月份的回应。
- Gemini 3.0 API 成本 描绘了 Google 的层级策略。
- Claude API 成本全解析 梳理了 Opus、Sonnet 和 Haiku 的定位。MiMo-7B 处于不同的生态位;请参阅 MiMo-7B-RL 基准测试 了解小米产品线中的小模型侧。
你的构建策略应如何调整
MiMo V2.5 的降价不是营销手段。它是对 1M-context 层级的结构性重新定价,且降价是永久性的。如果你之前因为成本原因推迟了长文档 RAG、全库代码 Agent 或任何需要 >200K-token context 的工作负载,你上个季度估算的预算可能比这个季度的实际需求高出了一个数量级。
三个具体的后续步骤:
- 按 token 消耗量提取你排名前三的工作负载,并按新的统一费率重新计算成本。那些运行长上下文的工作负载会让你感到惊喜。
- 针对 V2.5 Pro 和你当前的模型,使用相同的 prompts 进行 100 个样本的评估。大多数团队发现其质量区间对于 70% 到 85% 的流量是可以接受的。
- 搭建一个 Apifox 回归测试套件,这样下一次价格下调(肯定还会有的)时,评估工作只需几小时而非几周。
价格底线再次移动。请据此构建你的应用。
开发必备:API 全流程管理神器 Apifox
介绍完上文的内容,我想额外介绍一个对开发者同样重要的效率工具 —— Apifox。作为一个集 API 文档、调试、设计、测试、Mock、自动化测试于一体的工具,Apifox 是目前提升研发效率的首选。
如果你正在开发项目,不妨试试其极其友好的界面设计,它完全兼容 Postman 和 Swagger 数据格式,导入数据非常方便,,即使是新手也能很快上手,点击这里即可注册使用。
值得一提的是,除了个人和常规团队使用,针对有高安全合规要求、或需要在内网环境协作的企业,Apifox 还提供了深度定制的私有化部署方案。
获取专属报价与部署方案
 详细的私有化部署系统架构与安全白皮书
详细的私有化部署系统架构与安全白皮书
 针对您公司规模的专属报价单
针对您公司规模的专属报价单
 免费的 1v1 专属产品演示 (Demo) 机会
免费的 1v1 专属产品演示 (Demo) 机会

