Google 推出了 Gemma 3 270M,拥有 2.7 亿参数的“紧凑型”语言 AI 模型,是 Gemma 3 系列中最小的模型,专为设备端任务优化。我们可以借助它实现文本生成、问答、摘要和推理等功能,且所有操作都在本地完成。
Gemma 3 270M 支持 32,000 tokens 的上下文长度,能有效处理大量输入。同时,还融入了 Q4_0 量化感知训练(QAT)等量化技术,在保证质量的前提下降低了资源需求。因此它能达到接近全精度模型的性能,同时减少内存和计算量消耗。
然而,Gemma 3 270M 真正吸引人的地方在于易用性。你可以在标准硬件(笔记本电脑或者移动设备)上运行,提升隐私性和低延迟应用程序的性能。
Gemma 3 270M 的架构
Google 基于 Transformer 架构构建了 Gemma 3 270M,其中参数达 1.7 亿参数,词汇量达 25.6 万,Transformer 块包参数达 1 亿。此配置可支持多语言处理和特定领域任务。
受益于 INT4 量化、旋转位置嵌入和分组查询注意力等技术, Gemma 3 270M 可以提升推理速度,同时减轻模型负担。
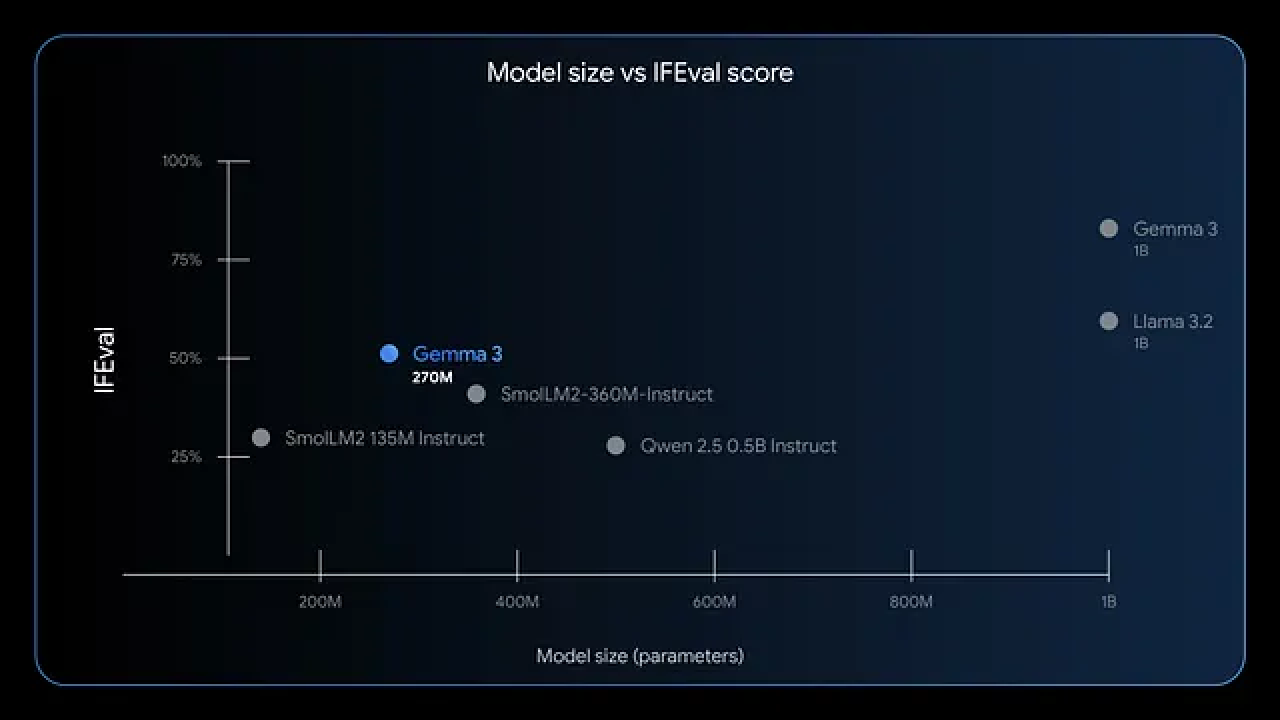
从上面这张模型大小与 IFEval 分数对比图能够看出 Gemma 3 270M在指令遵循和数据提取方面表现出色。测试显示,它在 IFEval 上的 F1 分数很高,表明在评估任务中性能强劲。与 GPT-4 或 Phi-3 Mini 等更大规模的模型相比,Gemma 3 270M 更注重效率,毕竟在 Apple M4 Max 等设备上,4 位模式下仅占用不到 200MB 内存。
你可以将它部署在需要快速响应的场景中,比如应用于创意写作或文档的合规检查。那么接下来,我们来评估本地运行这款模型的优势。
本地运行 Gemma 3 270M 的好处
- 增强隐私:使用 Gemma 3 270M 可以将数据保存在设备上,避免存在泄露风险的云传输
- 降低延迟:Gemma 3 270M 能将响应时间从秒级缩短至毫秒级
- 削减成本:使用 Gemma 3 270M 无需为云 API 支付订阅费用
- 能效突出:在 INT4 量化模式下,进行 25 次对话仅消耗 Pixel 9 Pro 0.75%的电量,适合移动设备和边缘计算场景
本地运行还能为小型团队或独立开发者赋能。你可以自由实验,反复迭代应用,比如电商查询路由或法律文本结构化处理。接下来,我们来看看你的系统是否满足运行要求。
Gemma 3 270M 本地系统条件
Gemma 3 270M 对硬件要求不高,因此很容易上手。Windows、macOS 或 Linux 操作系统都能运行该模型,但需确保安装 Python 3.10+以保证库兼容性。
如果只使用 CPU 进行推理,需要:Windows:
- 至少 4GB 内存
- Intel Core i5 或同等级别的现代处理器
- 2GB 显存的 NVIDIA 显卡
macOS: - 可借助 MLX-LM,在 M4 Max 上实现每秒 650 tokens 以上的处理速度
- 分配 8GB 内存
- 4GB 显存的 GPU
总的来说,在 4 位模式下,模型仅需 200MB 内存就能运行,适合资源有限的设备。
满足这些条件后,你就能顺利安装和运行模型了。现在,我们来看看安装方法。
选择合适的工具在本地运行 Gemma 3 270M
有多个框架支持 Gemma 3 270M,各有优势:
- Hugging Face Transformers 为 Python 脚本编写和集成提供了灵活性
- LM Studio 则提供了用户友好的界面,方便模型管理
- llama.cpp 支持基于 C++的高效推理,非常适合底层优化
- 对于 Apple 设备,MLX 能优化 M 系列芯片的性能
你可以根据自身需求选择工具:初学者适合 LM Studio,开发者则更适合 Transformers。
1. 使用 Hugging Face Transformers 运行 Gemma 3 270M
首先,安装必要的库。打开终端,执行以下命令:
pip install transformers torch该命令会获取 Transformers 和 PyTorch。
接下来,在 Python 脚本中导入组件:
from transformers import AutoTokenizer, AutoModelForCausalLM加载模型和分词器:
model_name = "google/gemma-3-270m"
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModelForCausalLM.from_pretrained(model_name, device_map="auto")device_map="auto"会在有 GPU 的情况下自动将模型部署到 GPU。
准备输入内容:
input_text = "用简单的语言解释量子计算。"
inputs = tokenizer(input_text, return_tensors="pt").to(model.device)生成输出:
outputs = model.generate(** inputs, max_new_tokens=200)
response = tokenizer.decode(outputs[0], skip_special_tokens=True)
print(response)这样就能生成连贯的解释。
要优化性能,可以添加量化处理:
from transformers import BitsAndBytesConfig
quant_config = BitsAndBytesConfig(load_in_4bit=True)
model = AutoModelForCausalLM.from_pretrained(model_name, quantization_config=quant_config)量化能减少内存占用。
若要处理 gated 模型,需确保 Hugging Face 登录:
from huggingface_hub import login
login(token="你的_hf_token")你可以从 Hugging Face 账户获取 token。完成这些设置后,就能反复进行推理了。
不过,对于非 Python 用户,不妨试试 LM Studio。
2. 使用 LM Studio 运行 Gemma 3 270M
- 从 lmstudio.ai 下载并安装该软件
- 启动应用后,在模型中心搜索“gemma-3-270m”
- 选择 Q4_0 等量化版本并下载
- 准备就绪后,从侧边栏加载模型。调整设置:将上下文长度设为 32k,温度设为 1.0
- 在聊天窗口输入提示词并发送,LM Studio 会显示带 token 速度的响应
- 支持导出聊天记录,或通过集成工具进行微调
对于高级使用场景,可在设置中启用 GPU 卸载。LM Studio 会自动选择最佳来源,确保兼容性。这种方法适合视觉学习者。
3. 使用 llama.cpp 运行 Gemma 3 270M
llama.cpp 支持高效推理。克隆代码仓库:
git clone https://github.com/ggerganov/llama.cpp构建代码:
make -j从 Hugging Face 下载 GGUF 文件:
huggingface-cli download unsloth/gemma-3-270m-it-GGUF --include "*.gguf"运行推理:
./llama-cli -m gemma-3-270m-it-Q4_K_M.gguf -p "构建一个简单的AI应用。"可指定--n-gpu-layers 999等参数以充分利用 GPU。
llama.cpp 支持多种量化级别,能平衡速度和准确性。你可以结合 CUDA 为 NVIDIA 显卡编译:
make GGML_CUDA=1llama.cpp 在嵌入式系统中表现出色。现在,我们来看看模型的实际应用示例。
Gemma 3 270M 本地使用的最佳实践
你可以创建一个「情感分析器」。输入客户评论,模型会将其分类为正面或负面。
用 Python 编写脚本如下:
prompt = "分类:这个产品太棒了!"
inputs = tokenizer(prompt, return_tensors="pt")
outputs = model.generate(**inputs)
print(tokenizer.decode(outputs[0]))Gemma 3 270M 会输出“正面”。将其扩展到摘要生成:
text = "这里是长篇文章..."
prompt = f"摘要:{text}"
# 生成摘要在问答场景中,你可以提问:“气候变化的原因是什么?”
模型会解释温室气体的作用。在医疗领域,它能从病历中提取实体。这些用途展示了模型的多功能性。
你还能通过微调使来更个性化。
本地微调 Gemma 3 270M
微调能让模型更好地适应特定任务。
使用 Hugging Face 的 PEFT 库:
pip install peft加载 LoRA 配置:
from peft import LoraConfig, get_peft_model
lora_config = LoraConfig(r=16, lora_alpha=32, target_modules=["q_proj", "v_proj"])
model = get_peft_model(model, lora_config)准备数据集后进行训练:
from transformers import Trainer, TrainingArguments
trainer = Trainer(model=model, args=TrainingArguments(output_dir="./results"))
trainer.train()LoRA 所需数据量少,在普通硬件上也能快速完成训练。保存并重新加载适配器后,能提升国际象棋走法预测等自定义任务的性能。
Gemma 3 270M 的性能优化技巧
- 通过 4 位或 8 位量化可最大化速度
- 对多次推理使用批处理
- 建议将温度设为 1.0,top_k=64,top_p=0.95
- 在 GPU 上启用混合精度
- 处理长上下文时,谨慎管理 KV 缓存
- 使用 nvidia-smi 等工具监控显存
- 定期更新库以获取优化
通过这些调整,在合适的硬件上可实现每秒 130 tokens 以上的处理速度。要避免提示词中出现双重 BOS tokens 等常见问题。多加练习,你就能高效运行模型了!
总结
现在,你已经掌握了在本地运行 Gemma 3 270M 的知识。从设置到优化,每一步都在增强你的能力。不妨大胆实验、微调模型并部署应用,充分发挥它的潜力。像这样的小型模型,正在极大地推动 AI 的普及。
当你在本地成功部署 Gemma 3 270M 后,Apifox 能成为你高效开发的得力助手。Apifox 作为强大的 API 管理平台,可帮助你管理与 Gemma 3 270M 交互的 API 接口,通过自动化测试确保接口稳定性,还能实时调试 API 调用过程中可能出现的问题。无论是将模型能力集成到业务系统,还是搭建基于模型的创新应用,Apifox 都能简化开发流程,让你更专注于释放 Gemma 3 270M 的价值,轻松实现 AI 功能的落地与迭代。