Google 近期推出了全新的 Gemini 3 系列模型,其中 Gemini 3 Flash 以其卓越的性能和极具竞争力的成本优势,成为了开发者社区的焦点。它在保持前沿智能的同时,优化了处理速度和效率,尤其适合需要快速响应和高吞吐量的应用场景。这篇文章将带领你深入了解如何在 Python 环境中,高效地调用 Gemini 3 Flash API 接口,解锁它的强大能力。
快速上手 Gemini 3 Flash API
获取 API 密钥
在开始编码之前,你需要一个有效的 Gemini API 密钥。这个密钥是你访问 Google AI 服务的凭证。通常,你可以通过 Google AI Studio 平台注册并获取你的 API 密钥。获取密钥后,建议将其设置为环境变量 GEMINI_API_KEY,这样在代码中就不需要硬编码,更加安全和灵活。
Python SDK 安装与基础调用
Google 为 Gemini API 提供了官方的 Python SDK,使得调用接口变得非常直接。首先,确保你的 Python 环境中已经安装了 google-generativeai 库。
pip install -U google-generativeai
安装完成后,你就可以用几行代码快速体验 Gemini 3 Flash 的文本生成能力了。以下是一个简单的示例,展示了如何实例化客户端并向 gemini-3-flash-preview 模型发送请求。
from google import genai
import os
# 如果没有设置环境变量,也可以通过 client = genai.Client(api_key="YOUR_API_KEY") 传递
client = genai.Client()
# 定义要调用的模型,这里是 Gemini 3 Flash 的预览版
model_name = "gemini-3-flash-preview"
# 构建请求内容
prompt_content = "用一句话解释量子纠缠是什么?"
# 调用模型生成内容
response = client.models.generate_content(
model=model_name,
contents=prompt_content,
)
# 打印模型返回的文本内容
print(response.text)
这段代码展示了最基础的文本生成功能。generate_content 方法是与模型交互的核心,它接收模型名称和输入内容,并返回模型的响应。response.text 属性则可以获取模型生成的主要文本输出。
Gemini 3 Flash 的核心特性
Gemini 3 Flash 不仅仅是一个快速的模型,它还带来了一系列新的 API 特性,让开发者对模型的行为有更细致的控制。了解这些特性对于充分利用模型的能力至关重要。
思考级别 (Thinking Level) 的精细控制
Gemini 3 系列模型引入了 thinking_level 参数,允许你控制模型内部推理过程的最大深度。这直接影响到模型的响应速度、成本以及推理的严谨程度。对于 Gemini 3 Flash,除了 low 和 high 之外,还额外支持 minimal 和 medium 级别。
不同的思考级别适用于不同的场景,合理选择可以显著优化你的应用性能。下表总结了 Gemini 3 Flash 不同的 thinking_level 及其适用场景。
思考级别 (thinking_level) |
特性 | 适用场景 |
|---|---|---|
minimal |
极低延迟,几乎无内部思考。 | 简单查询、高吞吐量应用、聊天机器人。 |
low |
最小化延迟和成本。 | 简单指令遵循、快速响应。 |
medium |
平衡思考能力,适用于大多数任务。 | 默认选择,兼顾速度与推理质量。 |
high |
最大化推理深度,输出更严谨。 | 需要复杂推理、逻辑分析的任务。 |
在 Python 中设置 thinking_level,需要通过 config 参数传入 types.GenerateContentConfig 和 types.ThinkingConfig。
from google import genai
from google.genai import types
import os
client = genai.Client()
model_name = "gemini-3-flash-preview"
# 设置思考级别为 "minimal" 以追求最低延迟
response = client.models.generate_content(
model=model_name,
contents="如何用Python实现一个简单的Web服务器?",
config=types.GenerateContentConfig(
thinking_config=types.ThinkingConfig(thinking_level="minimal")
),
)
print(response.text)
需要注意的是,thinking_level 和旧版的 thinking_budget 参数不能同时使用,否则会返回错误。推荐使用 thinking_level 来获得更可预测的性能。
多模态输入处理 (Media Resolution)
Gemini 3 Flash 同样支持多模态输入,能够处理图片、视频、音频和 PDF 等多种数据类型。media_resolution 参数提供了对多模态视觉处理的精细控制,你可以根据输入内容的具体需求调整分辨率。
通过调整 media_resolution,你可以平衡模型的细节识别能力、Token 消耗以及延迟。例如,对于需要读取图片中细小文字的场景,可以提高分辨率。以下是一个将高分辨率图片作为输入并提问的示例。注意,media_resolution 参数目前仅在 v1alpha API 版本中可用,所以初始化客户端时需要特别指定 API 版本。
from google import genai
from google.genai import types
import base64
import os
# media_resolution 参数目前仅在 v1alpha API 版本中可用
# 初始化客户端时指定 api_version
client = genai.Client(http_options={'api_version': 'v1alpha'})
model_name = "gemini-3-flash-preview"
# 假设你有一张图片的 base64 编码数据
# 实际应用中,你需要从文件或网络加载图片并进行 base64 编码
# 这里用一个占位符代替实际的图片数据,你需要替换为有效的 base64 编码图片数据
# 例如,可以从一个小的 JPG 图片文件读取并编码:
# with open("path/to/your/image.jpg", "rb") as f:
# image_data_base64 = base64.b64encode(f.read()).decode('utf-8')
image_data_base64 = "YOUR_BASE64_ENCODED_IMAGE_DATA_HERE"
if image_data_base64 == "YOUR_BASE64_ENCODED_IMAGE_DATA_HERE":
print("请替换 YOUR_BASE64_ENCODED_IMAGE_DATA_HERE 为真实的图片 Base64 编码数据。")
else:
response = client.models.generate_content(
model=model_name,
contents=[
types.Content(
parts=[
types.Part(text="这张图片里有什么?"),
types.Part(
inline_data=types.Blob(
mime_type="image/jpeg", # 根据你的图片类型调整
data=base64.b64decode(image_data_base64),
),
media_resolution={"level": "media_resolution_high"} # 设置为高分辨率
)
]
)
]
)
print(response.text)
根据输入媒体类型和你的需求,推荐的 media_resolution 设置有所不同。例如,对于大多数图像分析任务,media_resolution_high 能够确保最佳质量;而对于文档理解,media_resolution_medium 通常就足够了。视频输入则对低分辨率进行了优化以节约 Token 消耗。
保持上下文的 Thought Signatures
Gemini 3 模型引入了 Thought signatures(思考签名)的概念,它们是模型内部思考过程的加密表示,用于在 API 调用之间维护推理上下文。特别是在执行函数调用(Function Calling)或图像生成/编辑等场景下,正确地回传这些签名对于模型保持其推理能力至关重要。
对于 Python SDK 的标准聊天历史记录,Thought Signatures 通常由 SDK 自动处理,无需手动管理,这大大简化了开发者的工作。但理解其背后的机制,可以帮助你处理一些特殊情况,例如从其他模型迁移对话痕迹时。如果确实需要绕过严格验证(例如,从其他模型迁移),可以使用特定的虚拟字符串 'context_engineering_is_the_way_to_go' 来填充 thoughtSignature 字段。
在标准文本生成或流式传输中,如果响应中包含 thoughtSignature,最佳实践是将其传回后续请求,以维持模型的最佳性能。在处理多步函数调用或图像编辑的对话流时,确保历史记录中包含所有接收到的 thoughtSignature 是避免 400 错误的必要条件。虽然 SDK 多数情况下会自动处理,但当你的应用逻辑复杂或需要手动构建对话历史时,要特别注意这一点。
结合工具的结构化输出
Gemini 3 Flash 模型支持将结构化输出与内置工具结合使用,例如 Google Search、URL Context 和 Code Execution。这意味着你可以让模型不仅生成结构化的 JSON 数据,还能在生成过程中利用外部工具获取实时信息或执行代码。
这个功能非常强大,它允许模型在回答问题时进行更复杂的操作。例如,让模型先通过 Google Search 查找最新信息,然后将查询结果解析成预定义的 JSON 格式。以下示例展示了如何定义一个 Pydantic 模型来规范输出结构,并让 Gemini 3 Flash 在生成内容时使用 Google Search 和 URL Context 工具。
from google import genai
from google.genai import types
from pydantic import BaseModel, Field
from typing import List
import os
# 定义一个 Pydantic 模型来规范输出的 JSON 结构
class MatchResult(BaseModel):
winner: str = Field(description="比赛的获胜者名称。")
final_match_score: str = Field(description="最终比分。")
scorers: List[str] = Field(description="得分球员/选手的名称列表。")
client = genai.Client()
model_name = "gemini-3-flash-preview"
response = client.models.generate_content(
model=model_name,
contents="搜索最近一次欧洲杯的所有细节,并以指定格式输出。",
config={
"tools": [
{"google_search": {}}, # 启用 Google Search 工具
{"url_context": {}} # 启用 URL Context 工具
],
"response_mime_type": "application/json", # 指定输出为 JSON 格式
"response_json_schema": MatchResult.model_json_schema(), # 使用 Pydantic 模型的 JSON Schema
},
)
# 将模型的响应文本解析为 MatchResult 对象
result = MatchResult.model_validate_json(response.text)
print(result)
print(f"获胜者: {result.winner}")
print(f"最终比分: {result.final_match_score}")
print(f"得分手: {', '.join(result.scorers)}")
通过这种方式,你可以确保模型返回的数据严格符合你的应用预期,极大地提升了模型的可用性和与外部系统的集成能力。Pydantic 库在这里起到了关键作用,它帮助我们定义清晰的数据结构,并能方便地将模型输出验证和转换成 Python 对象。
编程实践中的最佳技巧
掌握了 Gemini 3 Flash 的基本调用和核心特性后,如何在实际开发中更好地应用它呢?这里有一些实用的最佳实践和注意事项。
Prompt 策略优化
Gemini 3 作为一款强大的推理模型,其 Prompt 策略与以往的模型有所不同。简洁明了的指令是关键。模型对直接、清晰的指令响应最佳,过长或过于复杂的 Prompt Engineering 技术可能会导致模型过度分析,反而影响效果。
如果你需要模型以某种特定的风格(例如,更健谈、更正式)进行输出,请在 Prompt 中明确说明,例如“请像一个友好的助手一样解释”。另外,当处理大量数据时,将具体的指令或问题放置在数据上下文之后,并使用“基于以上信息……”之类的短语来引导模型,可以帮助模型将推理锚定在提供的数据上,从而获得更精确的回答。
迁移与兼容性考量
如果你正考虑从 Gemini 2.5 或其他模型迁移到 Gemini 3 Flash,一些关键点值得注意。Gemini 3 在推理能力上有了显著提升。如果之前为了强制 Gemini 2.5 进行推理而使用了复杂的 Prompt 工程(如思维链),现在可以尝试简化 Prompt,并配合 thinking_level: "high" 来利用 Gemini 3 原生更强的推理能力。
关于 temperature 参数,Gemini 3 的默认值 1.0 已是最佳设置。如果你的旧代码显式设置了 temperature(特别是为了确定性输出而设置为较低值),建议移除该参数,使用默认值,以避免在复杂任务中出现循环或性能下降的问题。在处理 PDF 或文档时,默认的 OCR 分辨率可能有所变化,如果遇到准确性问题,可以尝试将 media_resolution 显式设置为 high。虽然 Gemini 3 Flash 具有 100 万 Token 的超大上下文窗口,但在处理多模态内容时,如果 Token 消耗超出预期,可以通过手动降低 media_resolution 来进行优化。目前,图像分割、Google Maps 接地和计算机使用工具尚未在 Gemini 3 模型中得到支持。
值得一提的是,Gemini 3 Flash 提供了免费层级 (gemini-3-flash-preview),这为开发者提供了极佳的实验和开发环境。同时,对于使用 OpenAI 兼容层(compatibility layer)的用户,常见的参数也会自动映射到 Gemini 对应的参数上,例如 OpenAI 的 reasoning_effort 对应 Gemini 的 thinking_level,其中 reasoning_effort medium 映射为 thinking_level high。这为跨平台迁移提供了便利。
开发必备:API 全流程管理神器 Apifox
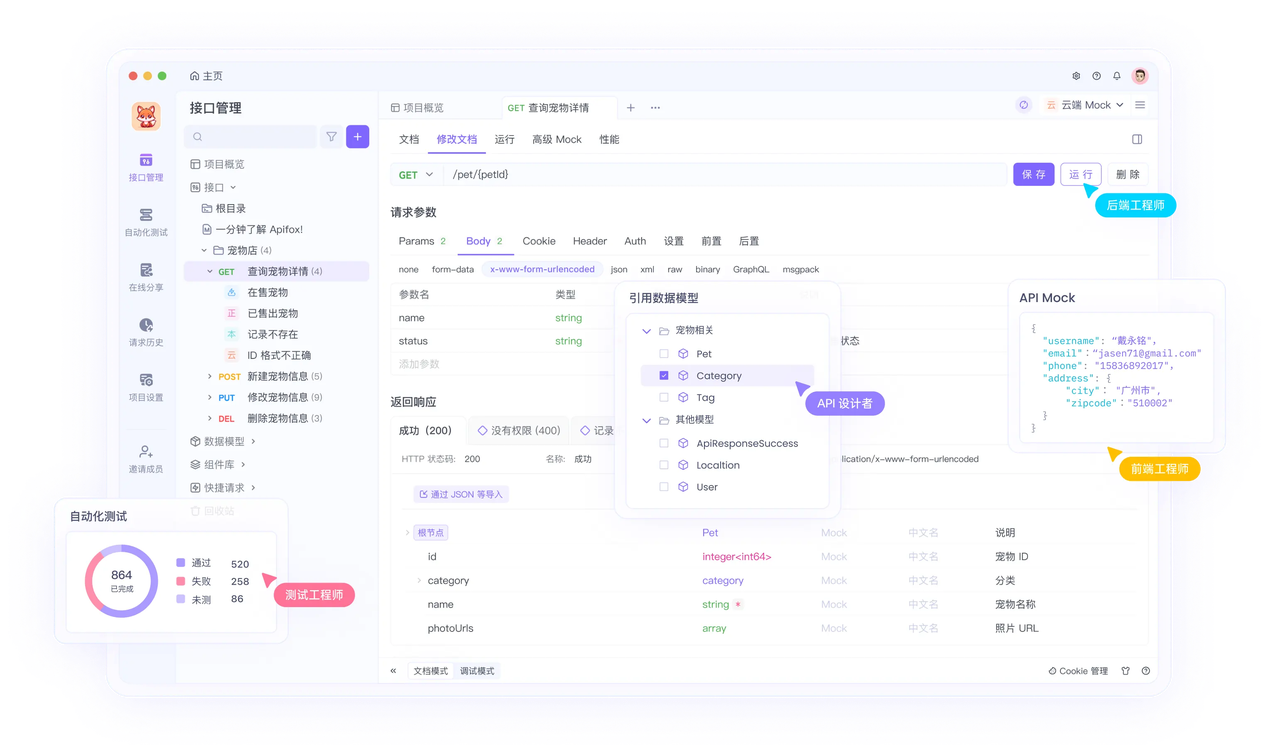
介绍完上文的内容,我想额外介绍一个对开发者同样重要的效率工具 —— Apifox。作为一个集 API 文档、API 调试、API 设计、API 测试、API Mock、自动化测试等功能于一体的 API 管理工具,Apifox 可以说是开发者提升效率的必备工具之一。
如果你正在开发项目需要进行接口调试,不妨试试 Apifox。注册过程非常简单,你可以直接在这里注册使用。
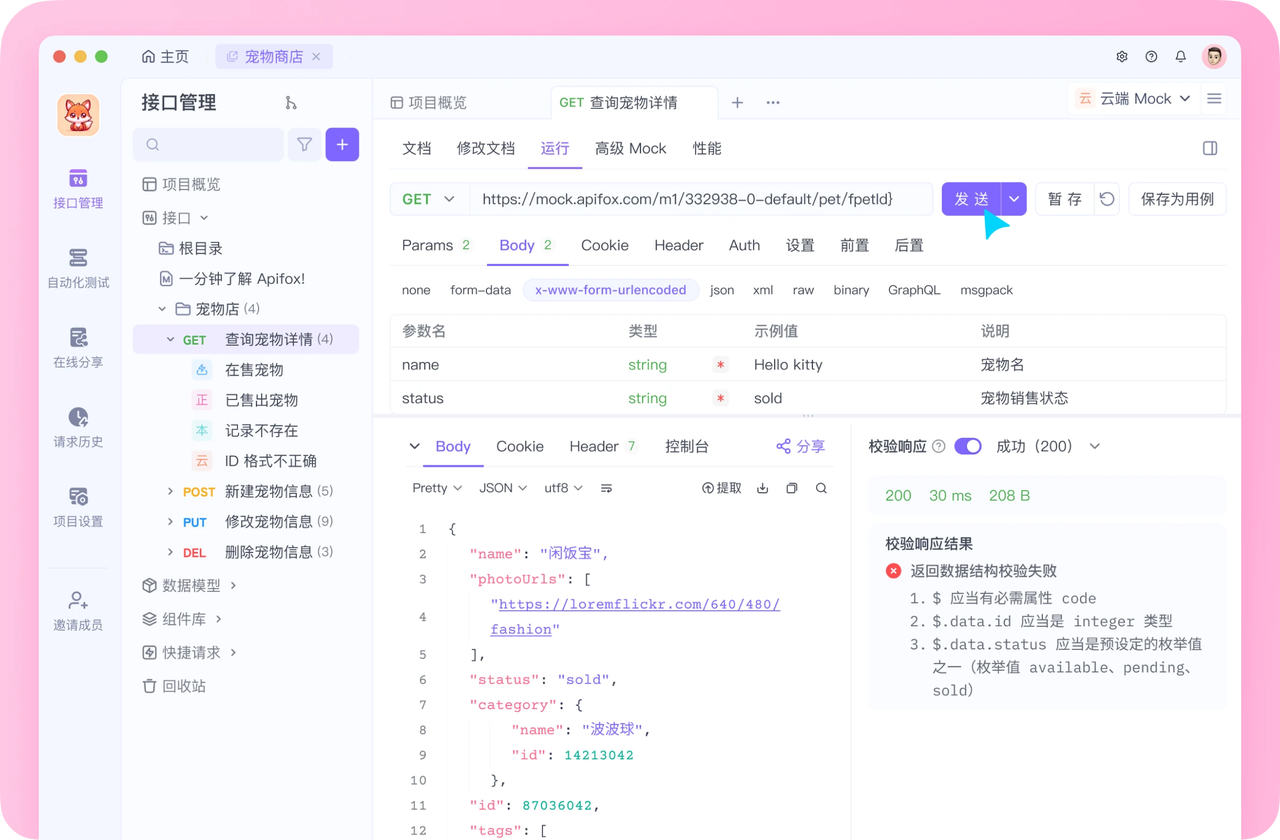
注册成功后可以先看看官方提供的示例项目,这些案例都是经过精心设计的,能帮助你快速了解 Apifox 的主要功能。
使用 Apifox 的一大优势是它完全兼容 Postman 和 Swagger 数据格式,如果你之前使用过这些工具,数据导入会非常方便。而且它的界面设计非常友好,即使是第一次接触的新手也能很快上手,快去试试吧!