在分布式系统的架构设计中,API 接口不仅是系统交互的通道,更是连接不同技术栈、组织文化乃至开发时代的契约。而在 RESTful API 的设计细节中,有一个看似微小却能引发无休止争论的话题:
JSON 字段名究竟该用 camelCase(小驼峰)还是 snake_case(下划线)?
这不仅仅是审美问题,它触及后端持久层与前端表现层之间的“阻抗失配”,牵涉到序列化性能、网络传输效率、开发者体验(DX)以及认知心理学。
本文将基于编程语言演进史、底层技术实现机制以及 Google、Stripe 等行业巨头的架构决策,为你提供一份专家级的决策指南。
历史溯源:符号学的选择
要理解这场争论,我们必须回溯计算机语言的发展脉络。命名规范并非凭空产生,而是特定时代硬件限制与社区文化的产物。
snake_case 的起源:C 语言与 Unix 哲学
snake_case(如 user_id)的流行可追溯到 70 年代的 C 语言和 Unix。当时的键盘设备(如 Teletype Model 33)虽然有大写键,但许多早期编译器对大小写不敏感。为了在低分辨率显示器上清晰地区分单词,程序员引入下划线模拟自然语言中的空格。这种习惯深深植根于 SQL 数据库标准中,至今 PostgreSQL 和 MySQL 的默认列名风格依然是下划线,这也为后来 API 与数据库的字段映射埋下了伏笔。
camelCase 的崛起:Java 与 JavaScript 的霸权
camelCase(如 userId)则随着面向对象编程(Smalltalk、C++、Java)兴起。Java 确立了“类名大驼峰,方法/变量名小驼峰”的工业标准。
决定性的转折点在于 JavaScript 的诞生。JSON 源自 JS 对象字面量,JS 标准库(如 getElementById)全面采用驼峰命名。随着 AJAX 和 JSON 取代 XML 成为数据交换霸主,camelCase 获得了 Web 领域的“原生”地位。
核心冲突:技术栈的阻抗失配 (Impedance Mismatch)
当数据在不同语言间流转时,不可避免地会遭遇“阻抗失配”。
后端视角的惯性(Python/Ruby/SQL)
- Python/Django/FastAPI:Pydantic 模型通常直接对应数据库表结构
class UserProfile(BaseModel):
first_name: str # 符合 Python 习惯
last_name: str
如果 API 强制返回 camelCase,就必须在序列化层配置别名(Alias)或转换器,增加了映射逻辑。
- SQL 数据库:绝大多数数据库列名使用 snake_case。API 使用 camelCase 意味着 ORM 层必须始终承担转换工作。
- Stripe 的选择:早期架构构建在 Ruby 栈上,直接暴露内部模型可保证后端一致性,因此坚持 snake_case。
前端视角的统治(JavaScript/TypeScript)
- 代码风格割裂:API 返回 snake_case,会破坏前端代码风格
const user = await fetchUser();
console.log(user.first_name); // 违反 ESLint camelcase 规则
render(user.email_address);
- 解构赋值的痛点:字段是 snake_case 时,需要繁琐重命名
const { first_name: firstName, last_name: lastName } = response.data;
这不仅增加样板代码,还提高出错概率。
性能迷思:序列化与网络传输
两个常见误区:
误区一:运行时转换开销
- 动态语言:Python 或 Ruby 中,频繁正则转换确实消耗 CPU,但现代框架(如 Pydantic v2,基于 Rust)通过预计算 Schema 映射,将开销降至极低。
- 静态语言 (Go/Java/Rust):转换几乎零成本,运行时只是简单字节拷贝。
注意:前端浏览器主线程不要做全局递归转换,否则会导致页面掉帧和内存抖动。
误区二:传输体积差异
- 理论上
first_name比firstName多一个字符,但开启 Gzip/Brotli 后差异几乎消失。 - 压缩算法利用重复字符串引用,JSON 数组中键高度重复,后续仅用短指针代替。
- 实测:Gzip 级别 6 下,两种风格 JSON 体积差异通常在 0.5%–1% 之间。
结论:传输体积不是问题,转换工作应由后端承担。
开发者体验 (DX) 与认知心理学
- snake_case 可读性优势:下划线提供清晰视觉分隔,处理连续缩写词时更易解析。例如
parse_db_xml比parseDbXml更快被理解。 - camelCase 一致性优势:全栈 JS/TS 团队统一 camelCase,可直接复用类型定义(Interface/Zod Schema),消除“脑内翻译”认知负荷。
行业巨头的标准与选择逻辑
| 公司 | 推荐风格 | 背景与逻辑 |
|---|---|---|
| camelCase | API 指南 (AIP-140) 强制 JSON 小驼峰,即使内部 Protobuf 为 snake_case,也会自动转换 | |
| Microsoft | camelCase | 随 .NET Core 与 TypeScript 的发展,全面转向 Web 标准 |
| Stripe | snake_case | Ruby 栈公司,通过完善 SDK 屏蔽差异,Node SDK 仍用下划线传输,但方法签名符合 JS 习惯 |
| JSON:API | camelCase | 社区规范推荐,Web 社区共识 |
深度架构建议:解耦与 DTO
反模式:直接透传数据库实体 → API 与 DB 强耦合,违反信息隐藏原则。
最佳实践:引入 DTO (Data Transfer Object) 层。
- 无论数据库如何命名,都定义独立 API 契约(DTO)。
- DTO 可统一使用 camelCase,现代映射工具(MapStruct, AutoMapper, Pydantic)可轻松处理转换。
面向未来:GraphQL 与 gRPC
- GraphQL:几乎 100% 使用 camelCase,REST API 若采用 camelCase,可前瞻性兼容。
- gRPC:Protobuf 文件字段定义用 snake_case,但 JSON 映射必须转为 camelCase,这是 Google 多语言环境的标准做法。
总结与决策矩阵
推荐方案
- 默认使用 camelCase
面向 Web/App 的新建 RESTful API,顺应 JSON/JS/TS 的统治地位,获得 IDE 与代码生成器最佳支持。
何时使用 snake_case?
- API 主要用户为 Python 数据科学家或系统运维(Curl/Bash)
- 遗留系统已经使用 snake_case,一致性优先
- 极度追求后端开发速度且无资源维护 DTO 层
决策一览表
| 维度 | 推荐风格 | 说明 |
|---|---|---|
| Web 前端 / 移动端 App | camelCase | 零阻抗,类型安全 |
| 数据分析 / 科学计算 | snake_case | 符合 Python/R 习惯 |
| Node.js / Go / Java 后端 | camelCase | 原生或库支持完美 |
| Python / Ruby 后端 | camelCase (建议配置转换器) 或 snake_case (内部工具) | 灵活选择 |
| 团队全栈化程度越高 | 越推荐 camelCase | 前后端统一,减少认知负荷 |
结语:API 设计的本质是同理心。在 Web API 语境下,将复杂性封装在后端,便捷性留给使用者,是专业而务实的选择。
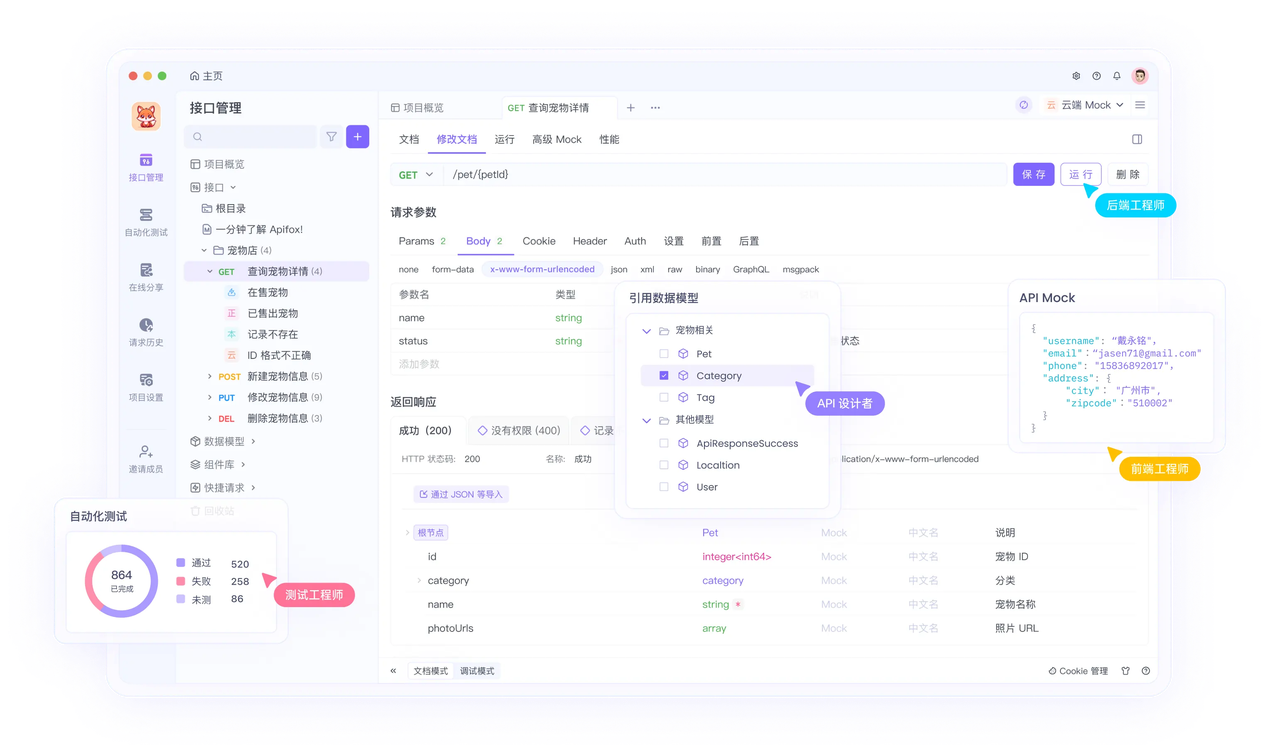
开发必备:API 全流程管理神器 Apifox
介绍完上文的内容,我想额外介绍一个对开发者同样重要的效率工具 —— Apifox。作为一个集 API 文档、API 调试、API 设计、API 测试、API Mock、自动化测试等功能于一体的 API 管理工具,Apifox 可以说是开发者提升效率的必备工具之一。
如果你正在开发项目需要进行接口调试,不妨试试 Apifox。注册过程非常简单,你可以直接在这里注册使用。
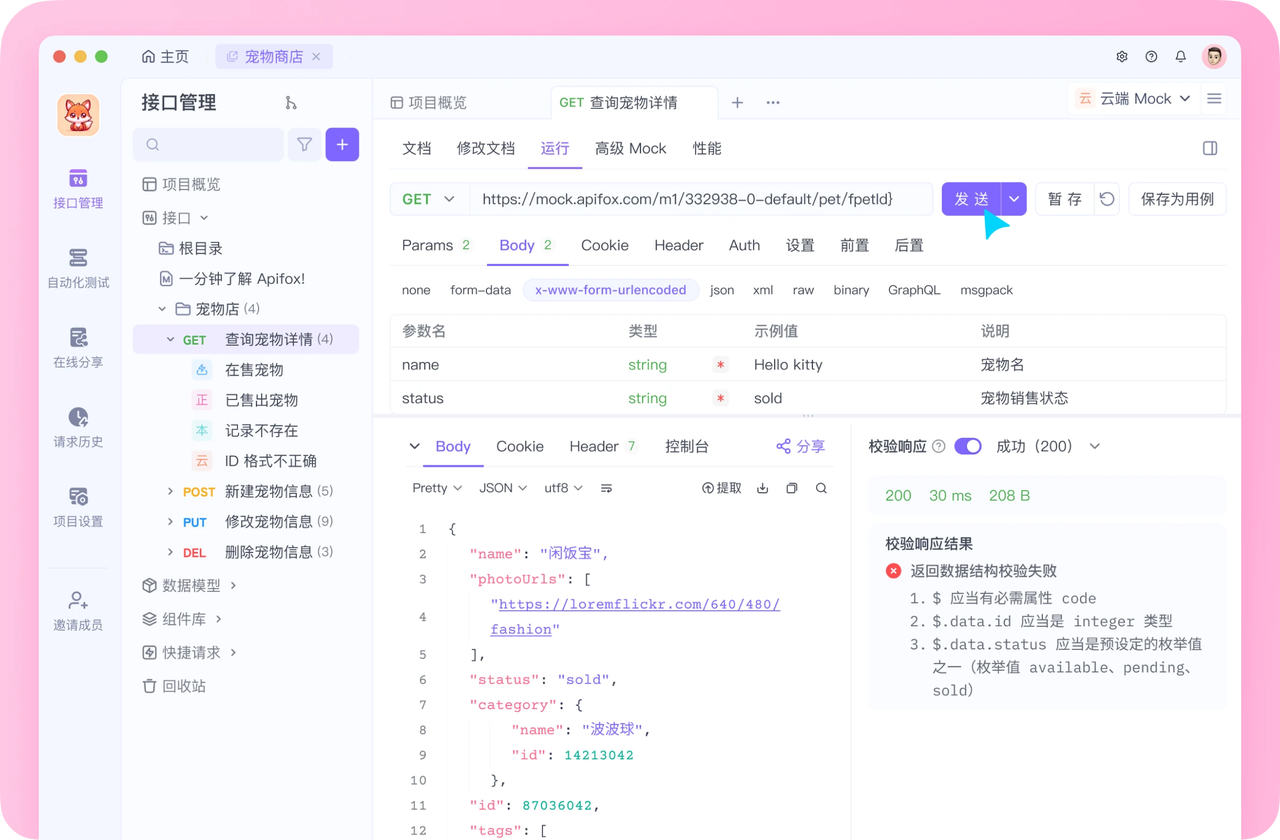
注册成功后可以先看看官方提供的示例项目,这些案例都是经过精心设计的,能帮助你快速了解 Apifox 的主要功能。
使用 Apifox 的一大优势是它完全兼容 Postman 和 Swagger 数据格式,如果你之前使用过这些工具,数据导入会非常方便。而且它的界面设计非常友好,即使是第一次接触的新手也能很快上手,快去试试吧!