你的笔记本电脑可以运行一个 70B 参数的模型,并提供与你发布到生产环境相同的 OpenAI 格式端点。只需更换一个基础 URL,你的代码就能继续工作。这一简单的改变解锁了离线开发、零 Token 成本以及受监管数据的私有化路径,这也是为什么 Hacker News 上“本地 AI 需要成为常态”的帖子在一天内从 633 分飙升至 1,760 分的原因。下文将向你展示如何选择运行时(Runtime)、暴露端点、配置客户端,并在将任何更改推送到托管模型之前,使用 Apifox 测试整个流程。
TL;DR
你可以使用 Ollama、vLLM 或 llama.cpp 在笔记本电脑上运行本地 LLM API,它们都提供兼容 OpenAI 的 REST 端点。只需将现有 OpenAI 客户端中的 base_url 更改为 http://localhost:11434/v1,相同的代码即可在 Llama 3.3、DeepSeek V4 或 Qwen 3.6 上运行,无需重写。通过 Apifox 驱动整个流程,使你的场景测试在本地和托管环境之间保持一致。
简介
本地 LLM API 技术栈在 18 个月内从研究玩具变成了日常生产力工具。Apple 在 M3 Max 上提供了 128 GB 的统一内存(unified memory)。Ollama 的周下载量达到了一百万次。vLLM 的 GitHub Star 数突破了 30,000 大关。然而,最大的转变在于社交层面。现在所有主流的运行时都支持 OpenAI 的 /v1/chat/completions 格式。你不再需要维护两条客户端路径。同一个 SDK 调用可以根据环境变量指向 localhost 或 api.openai.com。
这对 API 开发者来说非常重要,因为你现有的工具链可以继续发挥作用。你在 Apifox 中的请求模板指向 https://api.openai.com/v1/chat/completions。切换基础 URL 变量,点击发送,你就能从运行在自己 GPU 上的模型中获得相同的 JSON 返回。没有新的 Schema,没有新的鉴权流程。如果你已经在按功能跟踪 API 支出,你可以将本地模型与托管模型进行 A/B 测试,观察成本曲线下降的同时延迟如何变化。
本指南将涵盖运行时选择、服务器设置、客户端连接、场景测试、量化(quantization)权衡,以及四种当前模型的成本与延迟对比表。代码示例已在 macOS 15.4 和 Ubuntu 24.04 上的 Ollama 0.6 和 vLLM 0.7 中通过测试。关于更广泛的选择,请参阅 2026 年最佳本地 LLM。文中所有主张的外部引用均位于底部。
为什么本地 LLM 对 API 开发者很有意义
你发布的代码会调用 LLM。你也会在飞机上、在 Wi-Fi 糟糕的会议现场以及在屏蔽了 *.openai.com 出站流量的客户网络内部调试这些代码。本地 LLM API 为你提供了一个镜像生产环境的开发环境,且无需依赖网络。
隐私问题是最受关注的。HIPAA、GDPR 和欧盟 AI 法案都将包含病人笔记、合同或生物识别标识符的 Prompt 视为用户数据。将这些负载发送到托管端点会建立一种你必须记录、审计和更新的数据处理关系。而一个从未离开你硬件的模型则完全跳过了这些文书工作。欧洲数据保护委员会 2024 年关于 AI 处理的指南指出,设备端推理消除了《通用数据保护条例》(GDPR)第 44 条下的大部分跨境传输义务。
成本优势则体现在另一个维度。一个团队每天通过 GPT-5.5 Instant 运行 5000 万个 Prompt Token,按每百万 Token 5 美元计算,每天大约支付 250 美元。同样的业务量在价值 4,500 美元的 M3 Max Studio 上运行,在满负荷运转 18 天后,其摊销成本将降至零(不计电费)。你可以在如何使用 GPT-5.5 Instant 中查看这些数字的详细分析,并将同样的计算方法应用到你自己的工作负载中。
第三个原因是确定性(determinism)。托管模型的权重会在你不知情的情况下发生变化。OpenAI 的模型弃用页面列出了过去 12 个月内的 11 次快照退役。而本地模型是磁盘上的一个文件。它在今天和三年后产生的 Logits 是一样的。当你的回归测试套件依赖于 LLM 输出时,这种稳定性至关重要。兼容 OpenAI 的端点改变了游戏规则,因为你不再需要为这种稳定性支付集成成本。你已经在使用的 SDK 依然有效。
三个提供兼容 OpenAI 端点的运行时
2026 年,四种运行时主导了本地 LLM API 领域。其中三个开箱即用提供兼容 OpenAI 的 REST 服务器。第四个是 llama.cpp,它通过其 llama-server 二进制文件提供该功能。请根据工作负载而非流行程度进行选择。
Ollama
Ollama 是最简单的入门方式。一个二进制文件,一个 CLI,一个运行在 11434 端口的 HTTP 服务器。它针对在单机上运行单个模型的开发者,并为你处理模型下载、GGUF 量化和 Prompt 模板化。
## 在 macOS 上安装
brew install ollama
ollama serve &
ollama pull llama3.3:70b-instruct-q4_K_M
ollama run llama3.3:70b-instruct-q4_K_M
一旦 ollama serve 启动,兼容 OpenAI 的端点就位于 http://localhost:11434/v1。它支持对话(chat)、嵌入(embeddings)和流式传输(streaming)。在 M3 Max 上运行 70B Q4_K_M 模型的吞吐量上限约为每秒 12 个 Token。较小的模型可以达到每秒 80 到 120 个 Token。Ollama 是单用户开发、演示和 CI 运行器的理想选择。
vLLM
vLLM 是生产级的选择。它使用 PagedAttention 和连续批处理(continuous batching)技术,使吞吐量比普通运行器高出两到四倍。它默认在 8000 端口提供服务,并在 /v1 暴露兼容 OpenAI 的 API。你可以在下方参考资料中的 Kwon 等人发表的 SOSP 2023 vLLM 论文中阅读架构细节。

pip install vllm
vllm serve meta-llama/Llama-3.3-70B-Instruct \
--port 8000 \
--gpu-memory-utilization 0.9 \
--max-model-len 8192
在单张 H100 上,vLLM 在并发请求下处理 Llama 3.3 70B 的速度约为每秒 2,400 个 Token。它需要 CUDA GPU 或较新的 AMD ROCm 显卡,且无法在 Apple Silicon 上运行,这使得它不适合笔记本电脑,但非常适合共享开发集群。
llama.cpp
llama.cpp 是开启了 GGUF 生态系统的 C++ 运行时。它可以运行在从 Raspberry Pi 5 到双 RTX-5090 平台的任何设备上。其 llama-server 二进制文件在 /v1/chat/completions 上支持 OpenAI 格式。

git clone https://github.com/ggerganov/llama.cpp
cd llama.cpp && make -j LLAMA_METAL=1
./llama-server -m models/llama-3.3-70b-q4_k_m.gguf \
--port 8080 --host 0.0.0.0 -c 8192 -ngl 99
-ngl 99 标志将所有层卸载(offload)到 GPU。llama.cpp 让你对量化、批处理和内存映射(memory mapping)拥有最大的控制权。当你需要将模型挤进 16 GB VRAM 或测试异构硬件时,它是最佳选择。
LM Studio 和 Jan 在 GUI 中封装了 llama.cpp,并在可配置端口上暴露 OpenAI 端点。它们对于团队中不需要接触终端但需要测试 Prompt 的非技术用户非常有用。
一个简单的 Python 脚本来检查端点是否工作:
from openai import OpenAI
client = OpenAI(base_url="http://localhost:11434/v1", api_key="ollama")
resp = client.chat.completions.create(
model="llama3.3:70b-instruct-q4_K_M",
messages=[{"role": "user", "content": "Reply with the word OK only."}],
)
print(resp.choices[0].message.content)
如果你看到 OK,说明运行时、端口和 SDK 契约都匹配。你已经准备好将端点接入你的工具链了。
使用 Apifox 测试你的本地 LLM
只有当你的测试套件能像访问生产环境一样访问本地 LLM API 时,它才是有用的。Apifox 通过请求模板上的环境变量来处理这个问题,这意味着一个项目可以覆盖两个目标。
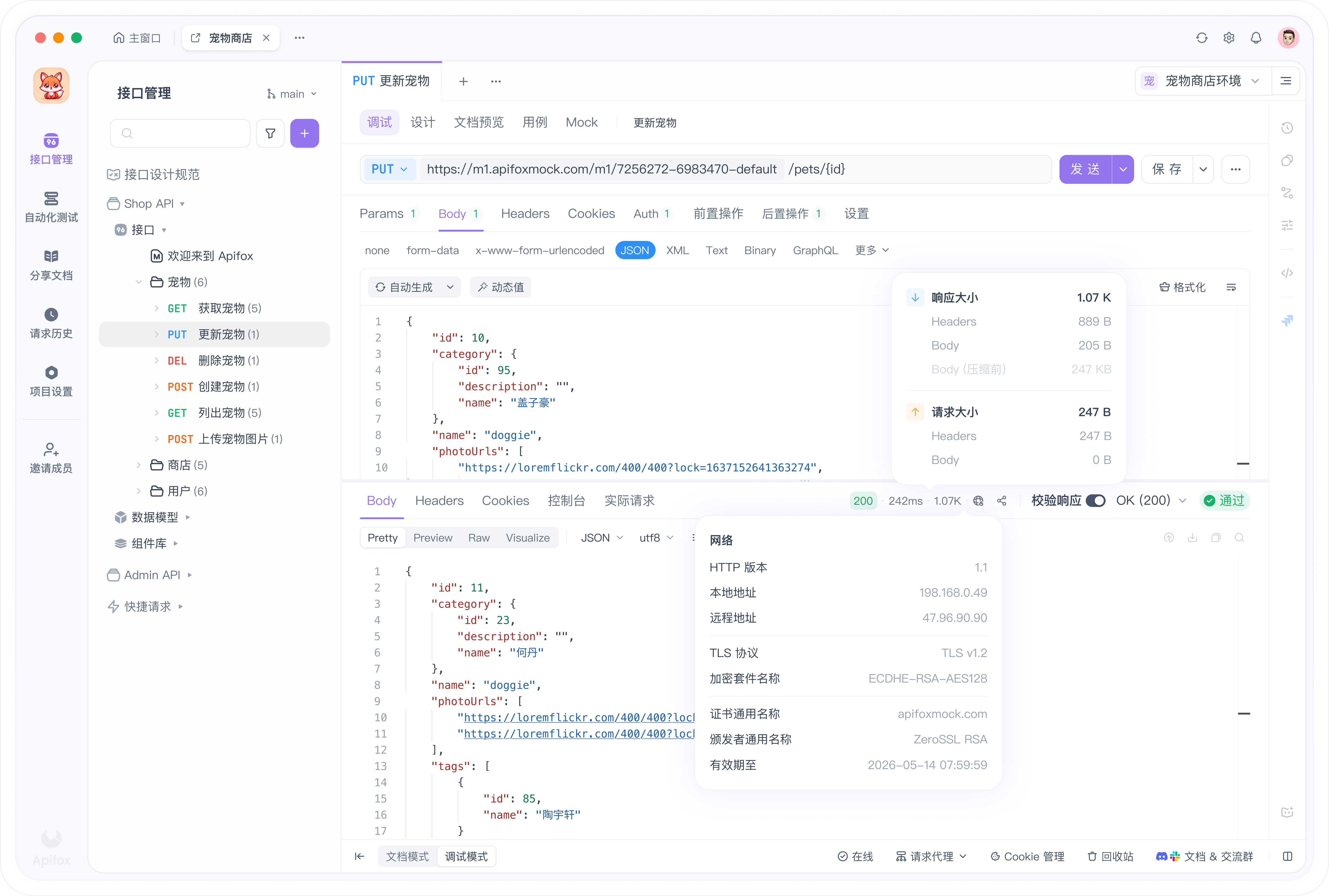
流程分为五个步骤:
- 打开你的 Apifox 项目,创建一个名为
Local的新环境。添加变量BASE_URL,值为http://localhost:11434/v1。添加API_KEY,值为ollama。保存。 - 克隆你现有的 OpenAI 环境,重命名为
Production,保持BASE_URL为https://api.openai.com/v1,API_KEY为你的托管密钥。 - 在任何调用对话端点的请求中,将硬编码的主机替换为
{{BASE_URL}},将认证头替换为Bearer {{API_KEY}}。请求 URL 变为{{BASE_URL}}/chat/completions。 - 构建一个场景测试,触发请求,断言
choices[0].message.role == "assistant",断言choices[0].message.content非空,并断言usage.total_tokens > 0。保存场景。 - 针对
Local环境运行场景。切换环境下拉菜单到Production。再次运行。两个环境的断言都应该通过。
同样的场景也可以作为运行时升级的冒烟测试。在对新标签执行 ollama pull 后,重新运行 Local 场景。如果响应格式发生偏移,你可以在任何应用程序代码接触新权重之前发现它。这种模式可以扩展到测试调用多步 API 的 AI Agent。
对于编程使用,OpenAI Python SDK 可以通过一个关键字参数切换目标:
import os
from openai import OpenAI
def get_client():
if os.getenv("ENV") == "local":
return OpenAI(
base_url="http://localhost:11434/v1",
api_key="ollama",
)
return OpenAI(api_key=os.environ["OPENAI_API_KEY"])
client = get_client()
response = client.chat.completions.create(
model=os.getenv("MODEL", "llama3.3:70b-instruct-q4_K_M"),
messages=[
{"role": "system", "content": "You are a JSON-only assistant."},
{"role": "user", "content": "Return {\"status\": \"ok\"}."},
],
response_format={"type": "json_object"},
)
print(response.choices[0].message.content)
JavaScript 的形式与之类似:
import OpenAI from "openai";
const client = new OpenAI({
baseURL: process.env.ENV === "local"
? "http://localhost:11434/v1"
: "https://api.openai.com/v1",
apiKey: process.env.ENV === "local" ? "ollama" : process.env.OPENAI_API_KEY,
});
const resp = await client.chat.completions.create({
model: process.env.MODEL || "llama3.3:70b-instruct-q4_K_M",
messages: [{ role: "user", content: "Say hi." }],
});
console.log(resp.choices[0].message.content);
通过将项目导出为 apifox-cli 集合并在 GitHub Actions 中调用 apifox run,将 Apifox 的场景运行器挂载到你的 CI 中。如果断言失败,运行器会返回非零退出码,从而在本地或托管契约发生偏移时立即导致构建失败。QA 工程师可以将相同的流程接入现有的 API 测试流水线。
高级技术与专家技巧
量化(Quantization)是决定 70B 模型能否装进笔记本电脑的关键。GGUF 格式以每个参数 8、6、5、4、3 或 2 位来存储权重。Q4_K_M 成为默认值是有原因的:与 FP16 相比,它在 MMLU 基准测试中仅损失 0.6 个百分点,并将 70B 模型从 140 GB 缩小到 40 GB。Q8 可以保持在 FP16 的 0.1 个百分点以内,但磁盘和 RAM 占用翻倍。Q2_K 虽然节省空间,但在长上下文任务中困惑度(perplexity)明显上升。对话建议选择 Q4_K_M,代码生成选择 Q8,当 RAM 充足且希望有安全余量时选择 Q5_K_M。
通过 llama.cpp 中的 -ngl 标志或 Ollama 中的 num_gpu 选项进行 GPU 卸载(GPU offload),可以控制有多少 Transformer 层驻留在 GPU 上。请将其设置为 VRAM 允许的最大值。每有一层回退到 CPU,吞吐量就会下降约 30%。在 24 GB 显存的卡上,70B Q4 模型可以容纳 80 层中的 40 层。在 48 GB 显存上,你可以容纳整个模型栈。
内存映射(mmap)在 llama.cpp 和 Ollama 中默认开启。它允许操作系统按需分页加载权重,而不是在启动时分配整个模型。除非你在内存限制严格的容器中运行,否则请保持开启。关闭 mmap 后,首个 Token 的延迟会降低约 200 毫秒,但 RAM 使用量会翻倍。
批处理(Batching)是 vLLM 的杀手锏。发送 32 个并发请求,vLLM 会将它们组合成单个 GPU 通道。吞吐量会随着 GPU 的计算上限近乎线性地扩展。对于共享 CPU 内存的笔记本电脑,设置 --max-num-seqs 64;对于 H100 级别的硬件,设置 --max-num-seqs 256。
流式响应(Streaming)可以将感知延迟减半。在 OpenAI SDK 中设置 stream=True,服务器会在 Token 生成时立即推送。首个字节会在 200 到 500 毫秒内到达,而无需等待完整生成。本指南中的每个运行时都支持此功能。
Ollama 的 Modelfile 允许你将系统提示词(system prompt)、温度(temperature)和停止序列(stop sequences)固化到一个命名的模型中,从而保持应用程序代码整洁。运行一次 ollama create my-assistant -f Modelfile,你的客户端就可以指向 my-assistant,而无需在每次请求时重复系统提示词。
常见错误
- 在生产代码中硬编码
http://localhost:11434。请使用环境变量。 - 忘记本地模型不强制执行
max_tokens。它们会很乐意生成 4,096 个 Token 的废话。请设置停止序列。 - 在同一个端口上运行 Ollama 和另一个运行时。虽然它们默认使用不同的端口,但自定义端口可能会发生静默冲突。
- 跳过
Authorization头。Ollama 会忽略它,但带有--api-key的 vLLM 会拒绝未经身份验证的请求并返回 401。 - 加载 Q4 模型并期望在数学任务上达到 GPT-5.5 的质量。量化对推理能力的侵蚀最快。
本地 vs 托管:成本与延迟计算
下表假设本地环境为 128 GB 统一内存的 M3 Max,托管端点采用当前的公开定价。首个 Token 时间(TTFT)是在冷启动、无批处理、1,024 Token Prompt 的情况下测得的。
| 模型 | 本地 TTFT | 本地吞吐量 | 托管等效模型 | 托管价格 (每 1M) | 托管 TTFT |
|---|---|---|---|---|---|
| Llama 3.3 70B Q4_K_M | 1.2 s | 12 tok/s | GPT-5.5 Instant | $5 / $30 | 200 ms |
| DeepSeek V4 67B Q4_K_M | 1.4 s | 10 tok/s | DeepSeek-Chat 托管 | $0.55 / $2.20 | 280 ms |
| Qwen 3.6 32B Q5_K_M | 0.7 s | 28 tok/s | Qwen-Max 托管 | $1.60 / $6.40 | 240 ms |
| Gemma 4 27B Q4_K_M | 0.5 s | 35 tok/s | Gemini 3 Flash | $0.35 / $1.05 | 180 ms |
托管列在延迟方面每次都胜出。而本地列在每天处理约 1000 万个 Token 时在成本上胜出,并且从第一个请求开始就在隐私方面胜出。对于开发阶段,你几乎总是想要本地模型。对于面向用户的生产环境,除非你的数据分类禁止这样做,否则你几乎总是想要托管模型。
一个实用的模式:在内部开发循环中运行本地模型,在预发布环境(staging)中切换到托管模型,并在 CI 中保持两个目标都通过。上一节中的 Apifox 场景测试通过简单的环境切换即可支持这种模式。关于单个模型的更深入基准测试,请参阅如何本地运行 DeepSeek V4 和原始的 DeepSeek V4 使用指南。
真实世界用例
新加坡的一家金融科技合规团队在工程师笔记本电脑上使用 Ollama 来起草可疑活动报告。Prompt 中包含账号和交易模式,根据 MAS(新加坡金融管理局)的规定,这些数据不能离开该国。他们在生产中使用的托管端点接收的是经过脱敏处理的相同 Prompt。Apifox 场景断言脱敏程序在每个请求离开 localhost 之前都会运行。
斯德哥尔摩的一家游戏工作室使用本地 Qwen 3.6 实例培训设计实习生的 Prompt 工程。免费、离线,且不可能将下一款游戏的背景设定泄露给第三方。同一个项目只需更改一个环境变量即可在生产环境中对接 Gemini 3 Flash。他们复用了 Gemini 3 Flash API 指南来进行生产环境的连接。
一家医疗保健初创公司在客户医院网络内部租用的 A100 上运行 vLLM。该端点从未暴露在公共 DNS 下。他们的集成测试由同一 VLAN 中的 Jenkins 代理运行,使用的是与本地相同的 OpenAI SDK。同样的代码,三个部署目标,一套场景测试。
结论
本地 LLM API 技术栈成熟得很快。你可以在不重写客户端、测试或 CI 的情况下,将 Prompt 从托管端点迁移出来。实现这一目标的五个步骤:
- 笔记本电脑选择 Ollama,共享开发集群选择 vLLM,内存预算紧张选择 llama.cpp。
- 暴露兼容 OpenAI 的端点,并使用单行 curl 进行验证。
- 将
base_url和api_key移入环境变量,使同一套代码能同时访问本地和托管环境。 - 在 Apifox 中构建场景测试,使其在两个环境中运行结果一致。
- 关注成本与延迟对比表,为每个工作负载选择合适的目标。
HN 上将“本地 AI 需要成为常态”推过 1,700 分的信号正是这种成熟度的体现。一旦 API 表面稳定下来,每个开发工具都会迅速跟进。下载 Apifox 并将一个环境指向 http://localhost:11434/v1,看看反馈循环闭合得有多快。如果你还没有选好模型,可以从 2026 年最佳本地 LLM 开始;如果你想深入了解如何在这些端点之上测试 Agent 流程,请阅读如何测试 AI Agent API。
开发必备:API 全流程管理神器 Apifox
介绍完上文的内容,我想额外介绍一个对开发者同样重要的效率工具 —— Apifox。作为一个集 API 文档、调试、设计、测试、Mock、自动化测试于一体的工具,Apifox 是目前提升研发效率的首选。
如果你正在开发项目,不妨试试其极其友好的界面设计,它完全兼容 Postman 和 Swagger 数据格式,导入数据非常方便,,即使是新手也能很快上手,点击这里即可注册使用。
值得一提的是,除了个人和常规团队使用,针对有高安全合规要求、或需要在内网环境协作的企业,Apifox 还提供了深度定制的私有化部署方案。
获取专属报价与部署方案
 详细的私有化部署系统架构与安全白皮书
详细的私有化部署系统架构与安全白皮书
 针对您公司规模的专属报价单
针对您公司规模的专属报价单
 免费的 1v1 专属产品演示 (Demo) 机会
免费的 1v1 专属产品演示 (Demo) 机会

