如果你曾参与过自动化测试,一定经历过那种即使代码没有任何修改,测试结果却显示失败的无力感。你 push 了自己精心编写的代码,确信没有任何问题,然后你启动了持续集成 (CI) ,等待出现熟悉的绿色对钩。然而最后得到的却是一个大大的红色 X。 你无法理解,疯狂地查看日志,却发现……一个随机测试失败了。你重新运行测试,但有时通过,有时不通过。
这说明什么?这说明你被一个不靠谱的测试坑了。
不稳定的测试非常浪费开发人员的时间,会严重拖慢 CI/CD 流程的速度,导致交付速度极其缓慢,并给团队带来巨大的损失。而且这是一个普遍存在的痛点,像谷歌等行业领导者已经发表了大量关于如何消除不稳定的测试的研究报告。
但不稳定的测试是有具体的、可识别的原因。而那些可识别的问题都可以修复。一旦你了解了它们的根本原因,就可以处理它们。
什么是不稳定测试(Flaky Tests)
在深入分析成因前,我们先明确「不稳定测试」的定义:不稳定测试(Flaky Tests)是在同一版本代码上多次运行, 既有通过的测试,也有失败的测试。它并非因为 bug 而持续失败的测试,而是随机失效的测试,会干扰对代码健康状态的判断。
举个例子:
- 第 1 次运行 → ✅ 通过
- 第 2 次运行 → ❌ 失败
- 第 3 次运行 → ✅ 再次通过
这类测试会引发一系列问题:
- 重跑循环赌运气:浪费开发者时间与 CI 资源
- 告警疲劳:频繁无意义的失败让团队逐渐忽视测试结果,导致真正的 bug 被遗漏
- 开发效率下降:构建失败与问题排查会拖慢整个团队的交付节奏
行业研究显示,部分企业甚至要花费 40%的测试时间处理测试不稳定性,这是巨大的资源浪费。
为什么不稳定测试对团队影响很大
你可能会想,“这只是一个测试失败了,重新运行它就好了。” 但问题是:
- 失去信任:开发人员不再信任测试结果
- 更慢的 CI/CD :管道因重试而堵塞
- 隐藏的错误:真正的问题被忽略了,会被统一认为是“不稳定而已”
- 成本增加:重播次数越多意味着需要更多的时间、资源和基础设施
根据行业研究,很多公司花费超过 40% 的时间用于测试处理不稳定因素,是非常浪费时间的行为!
不稳定测试的产生原因与解决方法
不稳定测试并不是随机事件,其背后都有明确成因。以下是最常见的十大问题及对应的解决方法:
1. 异步操作与竞态条件
这是导致测试不稳定的最大因素。现代应用中,API 调用、数据库操作、UI 更新等几乎都是异步的;若测试未等待这些操作完成就执行断言,本质上是猜测操作是否结束。有时操作快则测试通过,有时操作慢则测试失败。
成因:测试代码是同步执行的,但被测应用代码是异步的,两者节奏不匹配。
示例:测试点击“保存”按钮后,未等待网络请求完成就立即检查数据库,导致有时能查到新记录(请求快),有时查不到(请求慢)。
解决方案:
- 拒绝静态等待:绝对不要用
sleep()或setTimeout()。等待时间过短会失败,过长会拖慢测试; - 采用“条件等待”策略:根据具体场景等待特定条件满足:
- UI 测试:等待元素可见、可点击或包含指定文本(如 Selenium 的
WebDriverWait+expected_conditions,Cypress 内置自动等待); - API 测试:等待 HTTP 响应状态码符合预期,或数据库中出现目标数据。
2. 测试隔离性不足
若测试共享状态且不清理资源,就会互相影响。比如测试 A 创建了用户test@example.com却不删除,测试 B 再创建同名用户时,会因“唯一约束冲突”失败。
成因:数据库、缓存、文件系统等共享资源被某一测试修改后,未恢复初始状态,影响后续测试。
解决方案:
- 坚守“完全隔离”原则:每个测试都要独立创建所需数据,并在结束后彻底清理;
- 利用事务回滚:将测试放在数据库事务中,测试结束后回滚,确保数据库“零污染”;
- 生成唯一测试数据:用 UUID 或时间戳生成唯一标识(如
test.user.${timestamp}@example.com),避免数据冲突。
3. 依赖外部服务
若测试调用第三方 API(如支付接口、天气服务、邮箱验证),就等于把测试稳定性交给了不可控因素。外部服务可能卡顿、限流、维护,甚至微调响应格式,这些都会导致测试失败,且与你的代码无关。
成因:测试的成败依赖外部系统的健康状态,而外部系统不受控制。
解决方案:
- 优先使用 Mock/Stub 替代真实调用:拦截外部请求,返回预设的模拟响应(成功/失败场景均可覆盖);
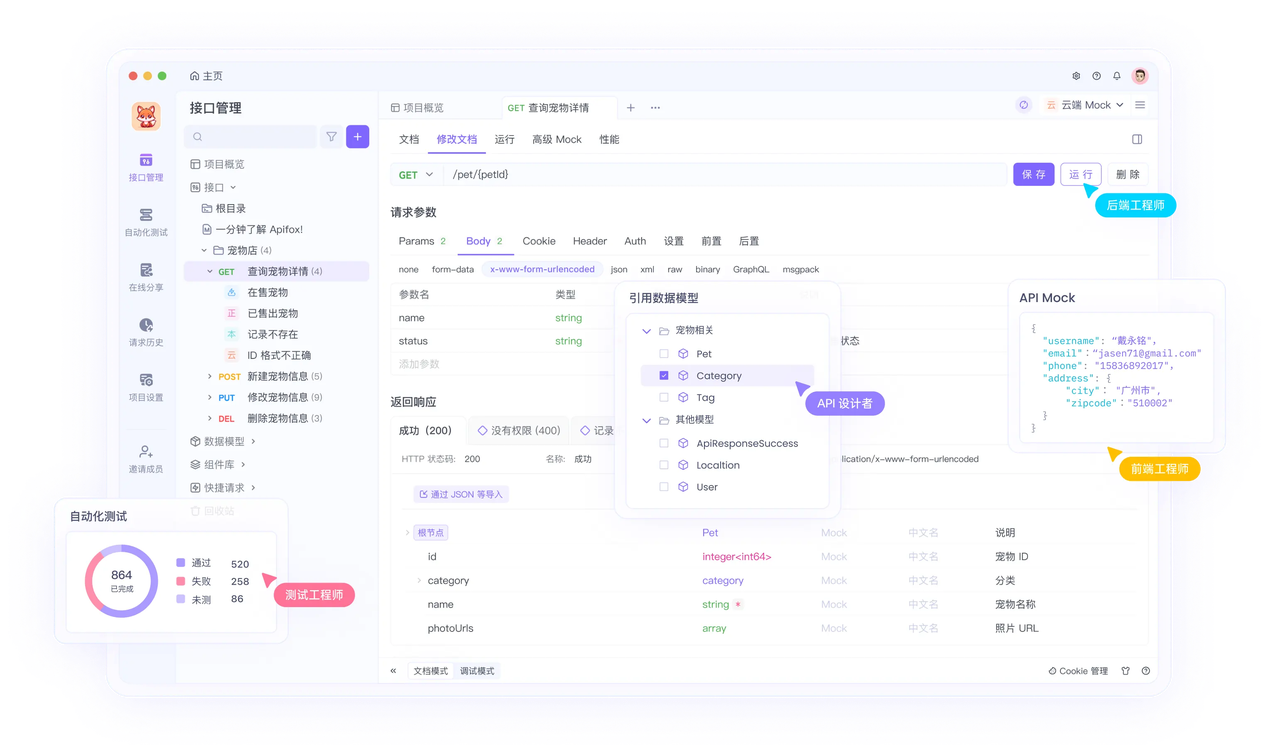
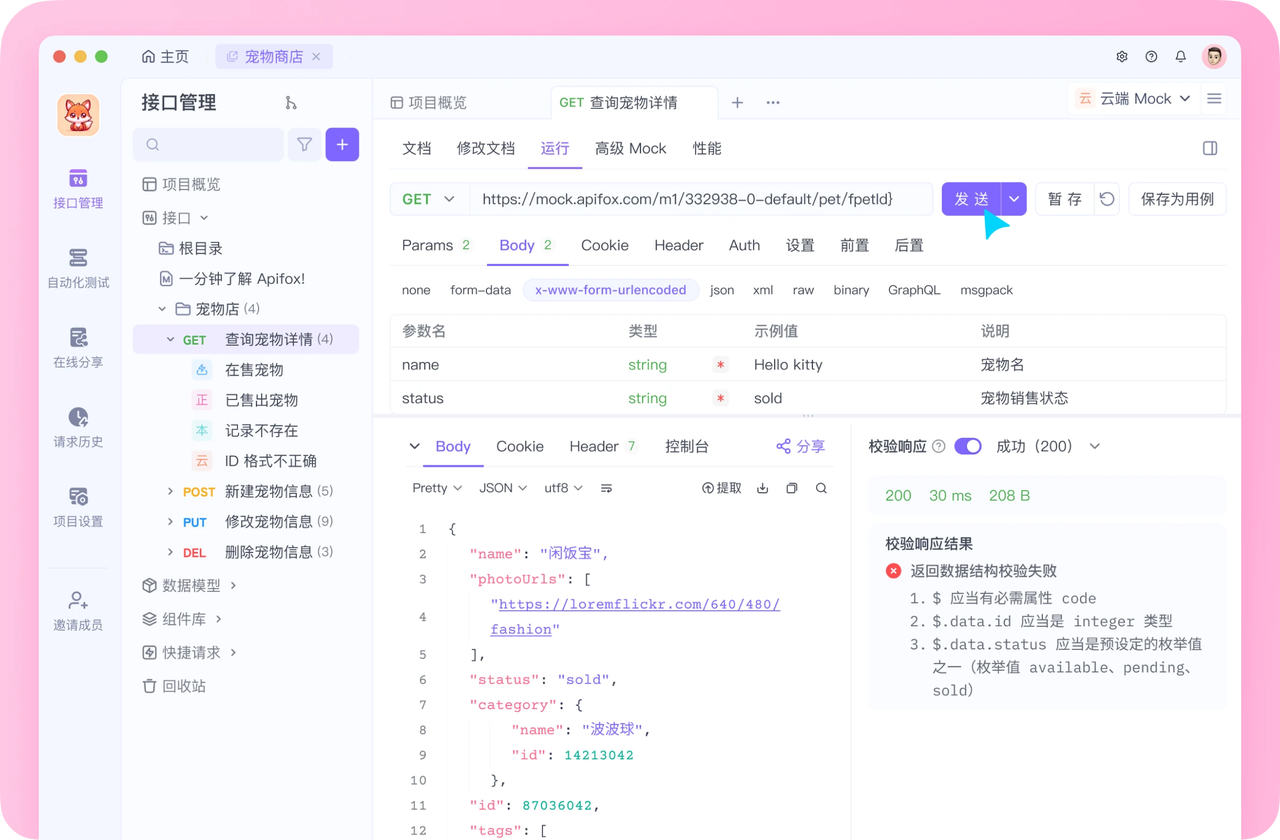
- 借助专业 Mock 工具:Apifox 是这类场景的理想选择——它能为 API 创建高仿真 Mock 服务,自定义请求与响应的映射关系,彻底摆脱对不稳定外部服务的依赖,让测试更快、更可靠;
- 复杂场景用服务虚拟化:对功能复杂的外部系统,可使用工具模拟其完整行为(如模拟支付网关的全流程)。
4. 测试数据未受控
若测试假设数据库处于特定状态(如“必须有 5 个用户”“ID 为 123 的产品存在”),一旦环境数据变化(如共享开发库被修改),测试就会失效。
成因:测试对环境数据有隐性假设,而假设随时可能不成立。
解决方案:
- 显式管理所有数据:测试绝不“想当然”,需自行创建所有依赖数据;
- 用工厂/夹具生成数据:借助
factory_bot(Ruby)、pytest fixtures(Python)等工具,快速生成测试所需的精准数据; - 拒绝硬编码 ID:不要依赖固定记录 ID,应在测试中创建记录后,使用其自动生成的 ID 进行断言。
5. 并发与并行测试冲突
并行运行测试是提升效率的关键,但若测试未针对并行场景设计,就会“互相踩踏”。比如两个测试同时访问同一文件、占用同一端口,或修改同一条数据库记录。
成因:测试被设计为“单线程运行”,但实际在多线程环境中执行,资源竞争导致失败。
解决方案:
- 从设计阶段考虑并行性:默认假设测试会并行运行;
- 资源隔离:为每个并行测试 runner 分配独立环境(如独立数据库 Schema、独立本地服务端口);
- 避免共享内存状态:确保测试中的内存操作是线程安全的,不依赖全局变量。
6. 依赖系统时间
若测试使用真实系统时间(如new Date()、DateTime.Now),运行时间不同会导致结果不同。比如检查“日报是否生成”的测试,在 23:59 运行通过,12:01 运行就会失败。
成因:系统时间是动态变化的外部输入,影响测试结果的确定性。
解决方案:
- Mock 系统时间:用工具“冻结”或“篡改”时间。如 Ruby 的
timecop、Python 的freezegun、Java 的Mockito.mockStatic,为测试设定固定时间,确保结果可复现。
7. 测试中存在非确定性代码
若被测代码包含随机逻辑(如随机数生成、列表打乱),测试无法对输出做稳定断言。比如断言shuffle()后的列表顺序,结果每次都不同。
成因:应用逻辑本身有随机性,导致测试输出不可预测。
解决方案:
- 固定随机种子:大多数随机数生成器支持设置种子,固定种子后“随机序列”会完全一致,测试即可确定性断言;
- 测试行为而非实现:不断言
shuffle()的具体结果,而是断言“输出列表包含所有输入元素,仅顺序不同”;或直接 Mock 随机逻辑,返回固定结果。
8. UI 选择器不足
前端测试的经典痛点:若测试用复杂嵌套选择器(如#main > div > div:nth-child(3) > button)定位元素,一旦开发调整 HTML 结构(如新增一个样式用div),选择器就会失效,即便功能本身正常。
成因:选择器与 DOM 结构强耦合,而 DOM 结构易变(如样式调整、组件重构)。
解决方案:
- 使用稳健的定位方式(优先级从高到低):
- 专用测试属性:优先用
data-testid(如<button data-testid="sign-up-btn">),完全脱离样式与结构; - 稳定 ID:若 ID 不用于 CSS 且长期不变,可使用(如
#submit-btn); - ARIA 角色或文本:适用于交互元素,但需注意多语言场景下文本变化;
- 绝对避免:基于 DOM 层级的复杂 CSS/XPath 选择器(如
div:nth-child(5))。
9. 资源泄漏与清理失败
测试若未正确关闭资源(如未释放数据库连接、未关闭浏览器实例、未删除临时文件),会导致后续测试因“资源耗尽”失败。比如数据库连接池满导致超时,或临时文件占用磁盘空间引发报错。
成因:测试缺少完善的“清理逻辑”,资源未被回收。
解决方案:
- 用钩子函数强制清理:借助测试框架的
beforeEach/afterEach(或类似钩子),确保无论测试成功与否,都能在结束后清理资源; - 用语言特性自动回收:如 C#的
using语句、Java 的try-with-resources,确保资源在使用后自动关闭。
10. 环境不一致
开发者本地与 CI 服务器的操作系统、浏览器版本、依赖库版本、环境变量不同,都会导致测试表现不一致。
成因:测试环境不可复现,存在“本地能过、CI 失败”的差异。
解决方案:
- 容器化环境:用 Docker 定义测试环境,通过
Dockerfile确保本地与 CI 的环境完全一致; - 依赖版本锁定:用
package-lock.json(Node.js)、Gemfile.lock(Ruby)、Pipfile.lock(Python)等文件,锁定所有依赖的精确版本; - 统一配置管理:用一致的方式管理环境变量与密钥,避免本地与服务器配置差异。
如何检测不稳定测试?
尽早发现不稳定测试是减少损失的关键,可采用以下策略:
- 自动重跑失败测试:若测试重跑后通过,标记为“疑似不稳定”
- 跟踪失败模式:分析 CI/CD 日志,识别反复失败的测试(如同一测试每周三下午失败)
- 隔离不稳定测试:为其添加标签,单独运行且不阻塞部署,同时安排时间修复
- 用工具监控:Jenkins、CircleCI、GitHub Actions 等工具均支持不稳定测试报告
用 Apifox 减少 API 相关的不稳定测试
许多不稳定测试与 API 或外部依赖相关,而 Apifox 能从根源解决这类问题:
- 稳定 Mock 服务:为外部 API 或未就绪的内部接口创建 Mock,避免依赖真实服务的波动;
- 自动化测试场景:用 Apifox 编排测试用例,确保 API 调用的输入输出可预测,减少随机失败;
- 性能测试预演:提前测试 API 在高负载下的表现,避免因 API 响应慢导致测试超时;
- 集中化测试管理:将所有API 测试集中在 Apifox,早期发现测试波动,定位不稳定根源(是代码问题还是依赖问题)。
避免不稳定测试的最佳实践
- 编写“确定性测试”,确保输入固定时,输出必然一致
- 对 API/网络请求使用 Mock/Stub
- 拒绝硬编码延迟,用“事件驱动等待”
- 每次测试后重置环境(数据、资源、配置)
- 长期监控测试表现,识别不稳定模式
- 记录已知不稳定测试,避免团队重复排查
修复单个测试只是治标,预防才是治本。所以需要团队共同重视测试可靠性:
- 零容忍不稳定测试:发现后立即“隔离”,不阻塞部署,但优先安排修复
- 跟踪不稳定测试清单:公开列出待修复的不稳定测试,明确优先级
- 代码审查关注测试质量:将测试代码与业务代码同等对待,审查时警惕上述“反模式”(如硬编码 ID、静态等待)
总结
不稳定测试是软件开发中最令人沮丧的问题之一,但绝非无法解决。它们浪费时间、侵蚀团队对测试的信任、拖慢交付。而只要针对性解决异步等待、测试隔离、外部依赖等十大核心问题,就能系统性消除不稳定因素,写出更健壮的测试。
而对于 API 相关的不稳定测试,Apifox 是你的强力助手。在实际 API 测试场景中,你用 Apifox 创建 Mock 服务模拟外部支付接口后,不仅能避免调试因支付服务波动失败,还能通过 Apifox 的自动化测试功能,批量验证“支付成功”“支付超时”“参数错误”等场景的测试用例;若后续接口逻辑调整,只需在 Apifox 中更新测试断言与 Mock 规则,即可快速适配,全程无需担心测试不稳定问题。赶快行动起来吧!