SFT最佳实践
1.
2.
3.
4.
5.
一、识别应用场景
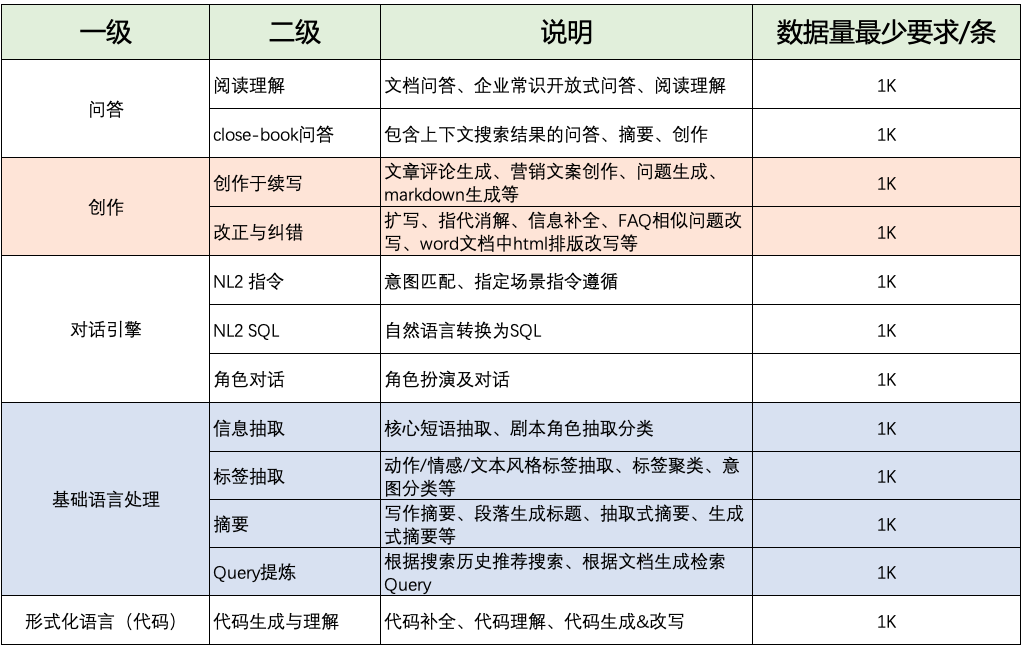
通用场景
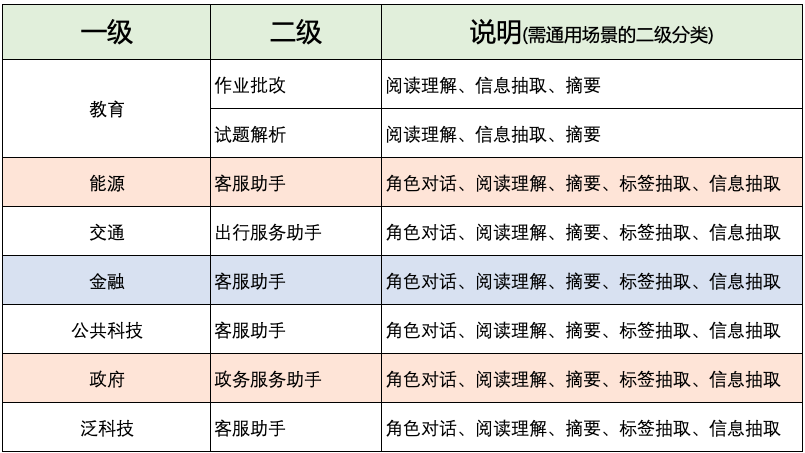
垂类场景
二、数据准备与微调
准备数据
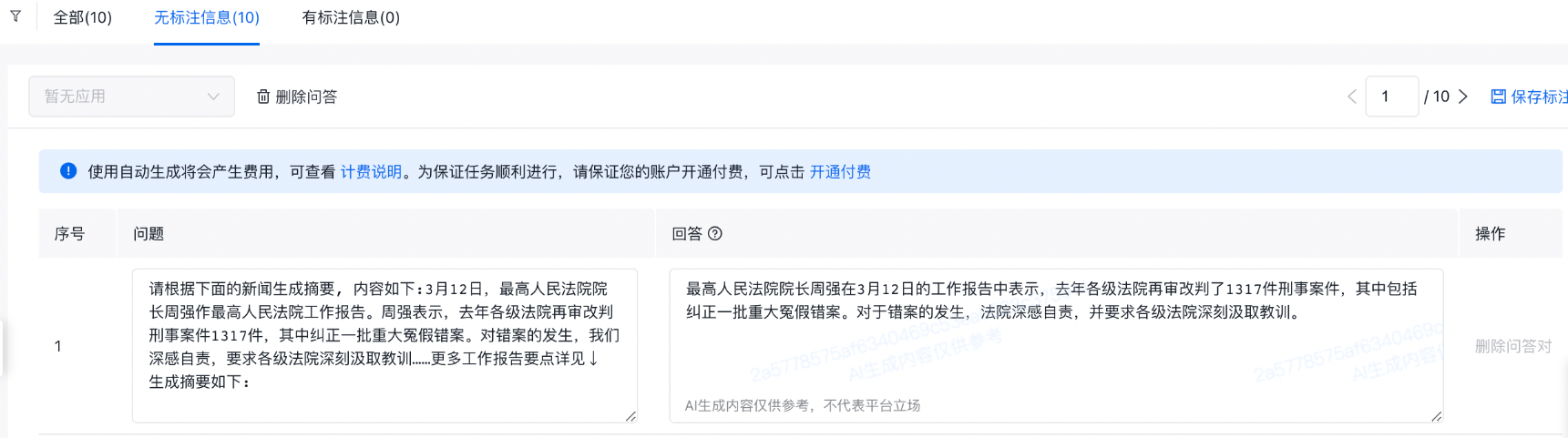
1.
2.
3.
三、训练配置
1 选择合适长度的模型

实际案例
prompt+reponse 平均长度: 2806
prompt+reponse 最大长度: 7652
prompt+reponse 最小长度: 554
prompt+reponse 超过4k的数据占比:23.36%
数据量:训练数据2w+条,预测数据700+条
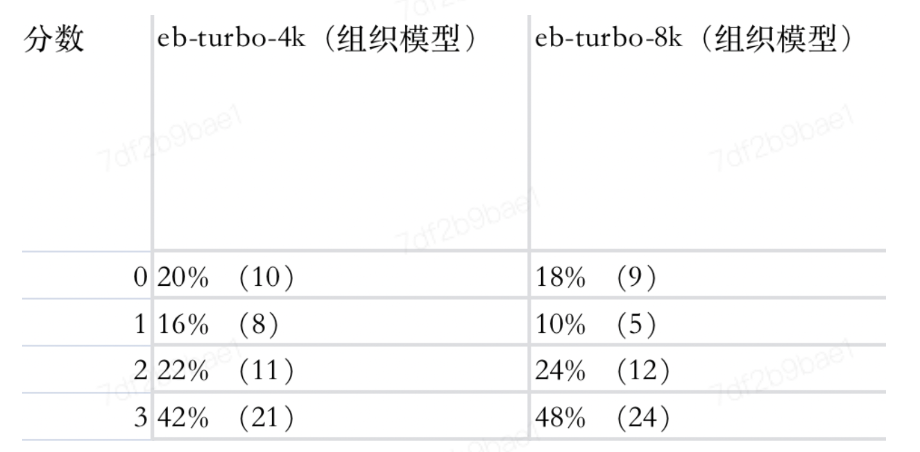
2 选择训练方法
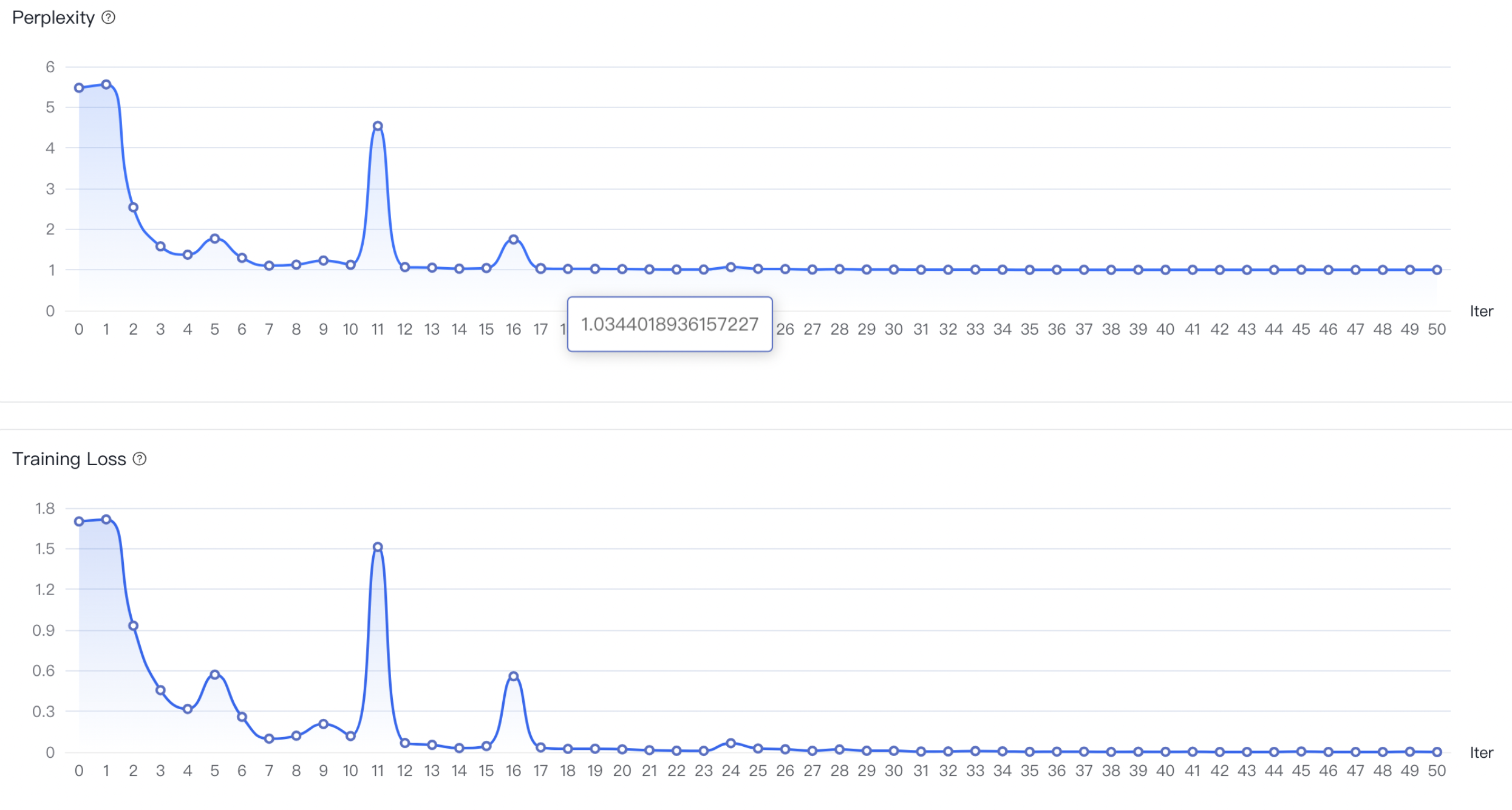
实际案例
3 配置超参数
实际案例
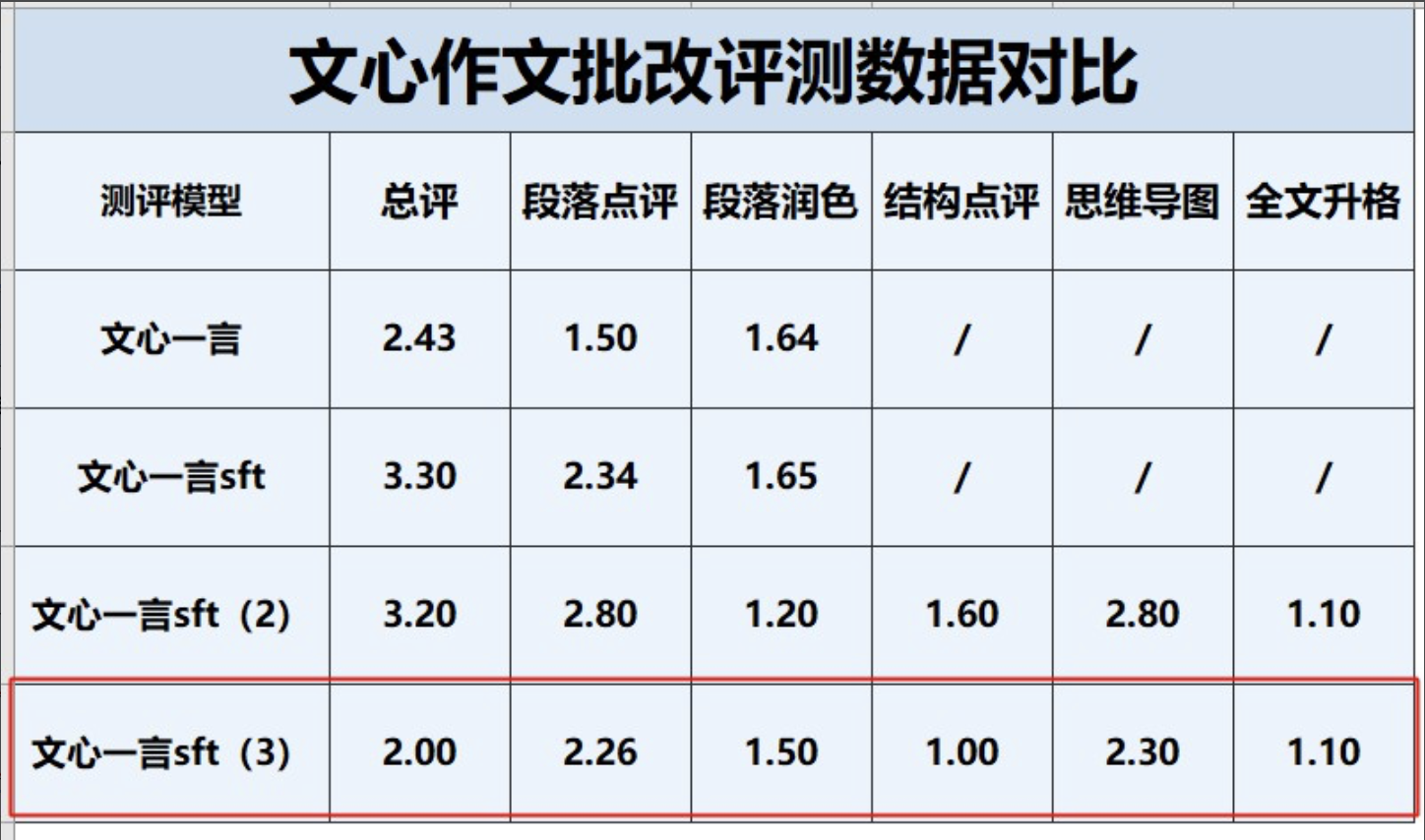
1.
2.
3.
如果测试的时候,都只会回答训练见过的内容,可能是训练过拟合了,需要调整数据或超参。
四、训练结果优化
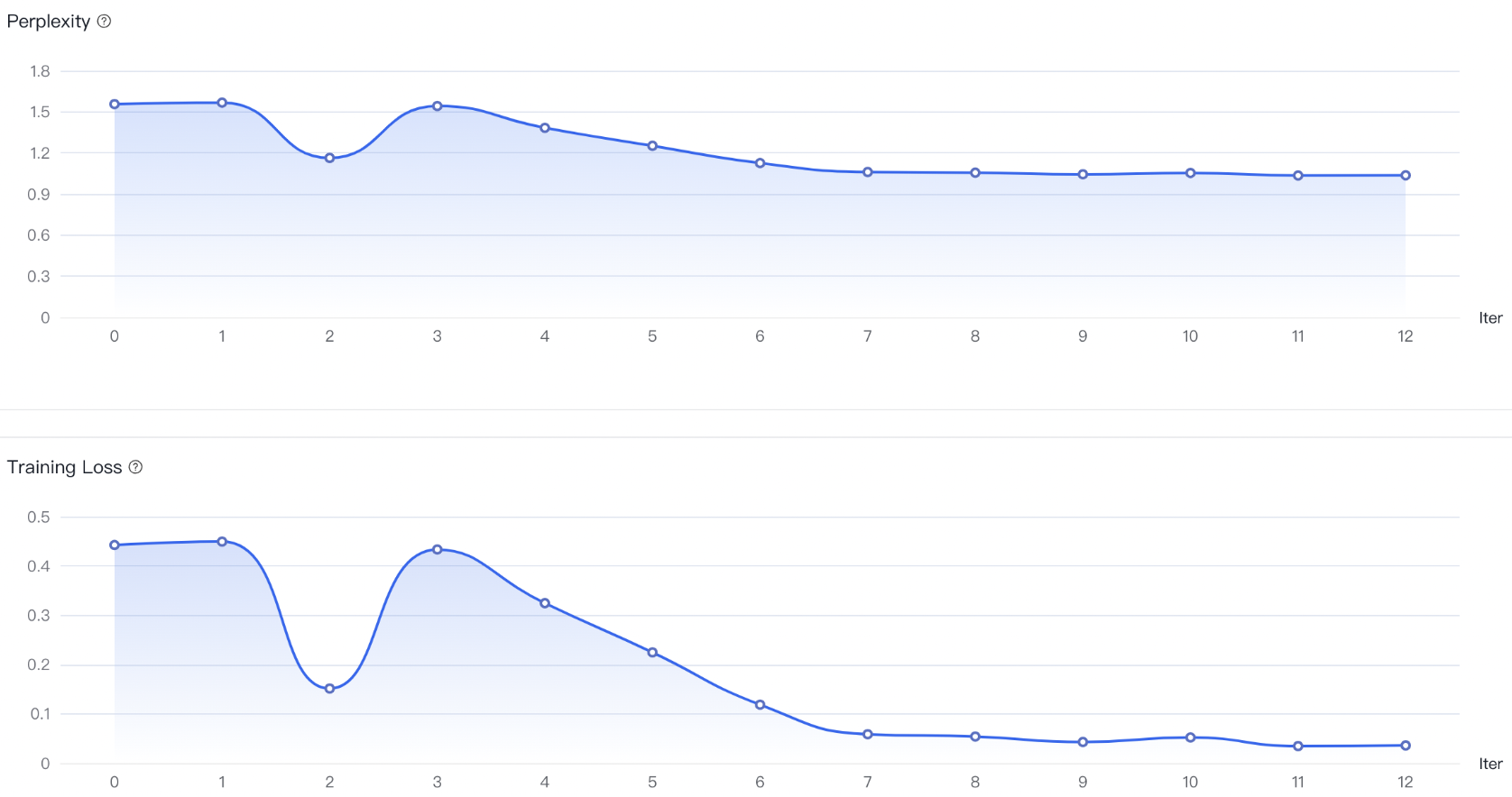
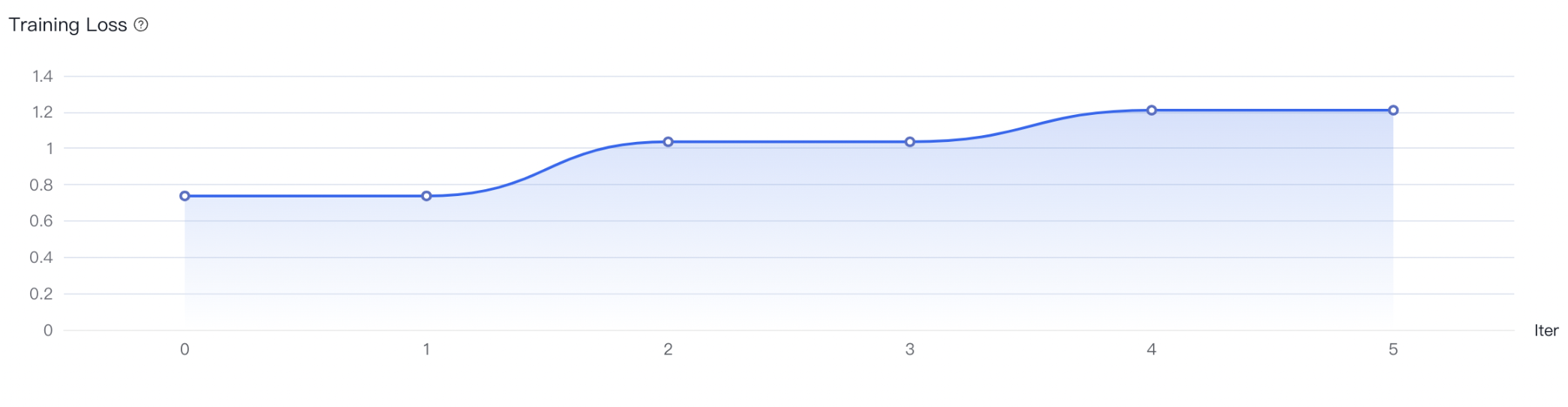
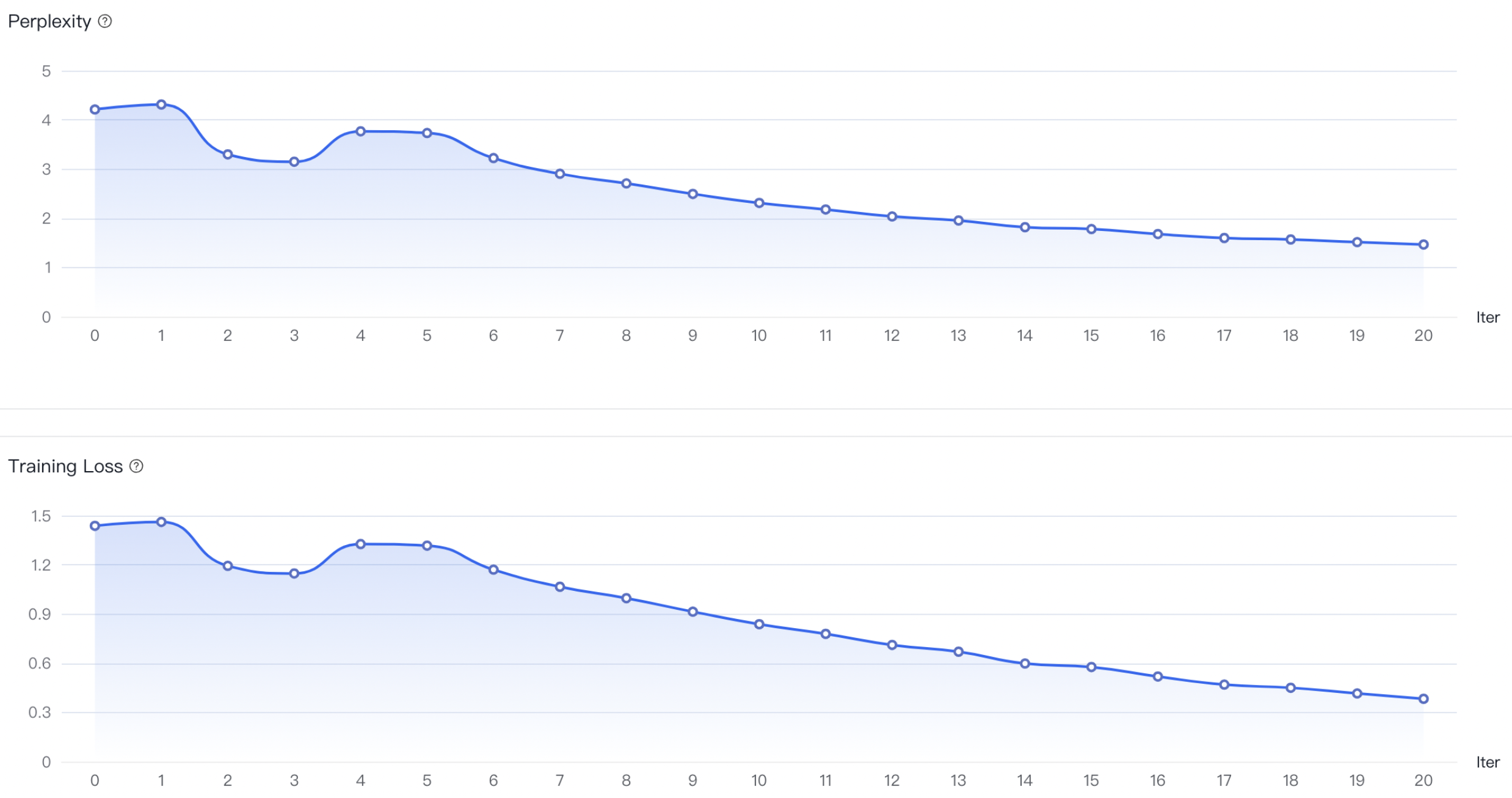
a)如果没有明显收敛,说明训练不充分,可以增加训练epoch重训,或者进行增量训练。
b)如果收敛出现在训练过程的前半部分,而后部分的loss平稳无变化,说明可能有过拟合,可以结合评估结果选择是否减少epoch重训。
c)如果有收敛趋势,但没有趋于平稳,可以在权衡通用能力和专业能力的前提下考虑是否增加epoch和数据以提升专业能力,但会有通用能力衰减的风险。
| 指标 | 说明 |
|---|---|
| BLEU-4 | BLEU-4 是NLP中机器翻译/⽂本摘要等生成类任务常⽤的评价指标,是将模型生成结果和标注结果分别按1-gram、2-gram、3-gram、4-gram拆分后,计算出的加权平均精确率(n-gram 指⼀个语句⾥⾯连续的n个单词组成的⽚段)。 |
| ROUGE-1 | ROUGE-1 是NLP中机器翻译/⽂本摘要等生成类任务常⽤的评价指标,是将模型生成结果和标注结果按1-gram拆分后,计算出的召回率(n-gram 指⼀个语句⾥⾯连续的n个单词组成的⽚段)。 |
| ROUGE-2 | ROUGE-2 是NLP中机器翻译/⽂本摘要等生成类任务常⽤的评价指标,是将模型生成结果和标注结果按2-gram拆分后,计算出的召回率(n-gram 指⼀个语句⾥⾯连续的n个单词组成的⽚段)。 |
| ROUGE-L | ROUGE-L 是NLP中机器翻译/⽂本摘要等生成类任务常⽤的评价指标,是将模型生成结果和标注结果按最长公共子序列(longest-gram)拆分后,计算出的召回率。 |
a. 简单的封闭任务例如标签抽取的任务,抽取prompt中的试题属于语文还是数学,response只有“语文试题”或者“数学试题”四个字。在这个任务中,大模型的回答是封闭的,且任务简单,ROUGE、BLEU指标都可以接近100满分。
b. 开放任务例如文本生成,按照用户的提示和材料生成一个故事。在这个例子中,评估指标能达到50-60已经是很好的结果了,在没有sft时指标甚至只有10-20。
五、训练持续迭代
实际案例


修改于 超过 1 年前