谷歌的 Gemini 模型家族最近迎来了新成员,其中 Gemini 3 Flash 和 Gemini 3 Pro 备受关注。虽然它们都属于 Gemini 3 系列,但其设计初衷和适用场景却有着明显的不同。简单来说,一个追求极致的速度和成本效益,另一个则专注于提供顶级的推理能力。
这篇文章将深入探讨这两款模型的核心区别,帮助你理解它们的定位,并在实际应用中做出正确的选择。

定位与设计哲学
Gemini 3 系列的推出,标志着谷歌在 AI 模型能力上的又一次跃进。在这个系列中,Gemini 3 Pro 承载了最前沿、最复杂的推理任务,是追求极致性能的代表。它的设计目标是解决最具挑战性的问题,无论是在多模态理解、复杂逻辑推理还是代码生成方面,都力求达到当前技术的顶峰。
与之相对,Gemini 3 Flash 的设计哲学则是在“速度”和“成本”上做文章。它并非 Pro 模型的简单降级版,而是一款经过精心优化的轻量级模型。Flash 的目标是在保持“Pro 级别”核心智能的同时,大幅提升响应速度并降低使用成本,使其能够被广泛应用于高频、交互性强的场景中。
性能与智能的权衡
提到轻量级模型,很多人会联想到性能上的妥协。但 Gemini 3 Flash 的表现可能会颠覆这种认知。它在多个关键基准测试中,展现了与更大规模模型相媲美的实力。
Flash 的 "Pro 级" 推理能力
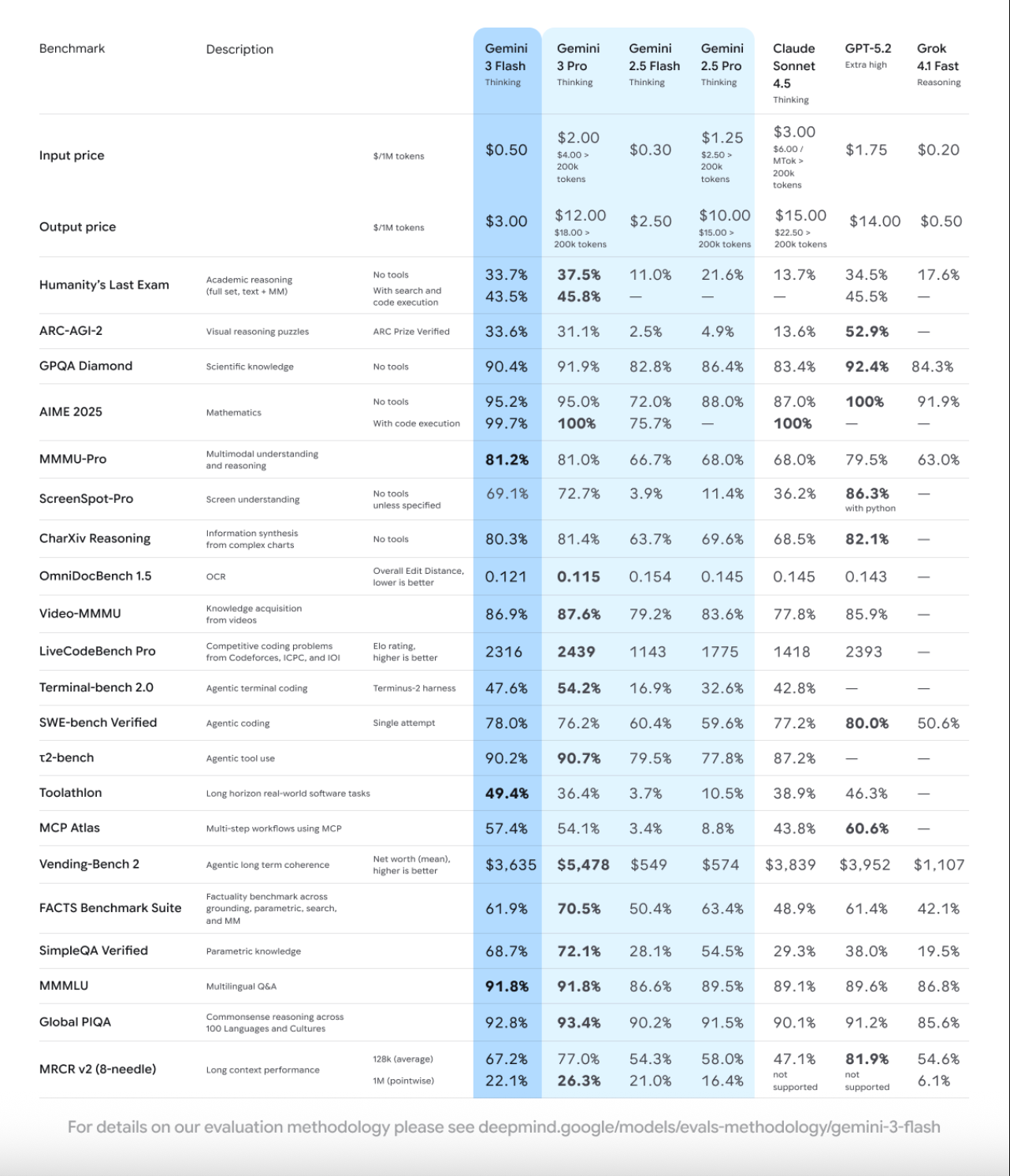
谷歌官方数据显示,Gemini 3 Flash 在博士级别的推理和知识基准测试中表现出色。例如,在 GPQA Diamond 测试中获得了 90.4% 的高分,在 MMMU Pro(一个衡量多模态理解能力的权威基准)上取得了 81.2% 的成绩,这已经与 Gemini 3 Pro 的表现相当。
这说明 Flash 在核心推理能力上并未做出巨大牺牲,它依然能够处理复杂的分析和理解任务。这种能力源于其高效的模型架构,使其在处理复杂问题时可以动态调整“思考深度”,在确保准确性的前提下优化资源消耗。
速度与效率的优势
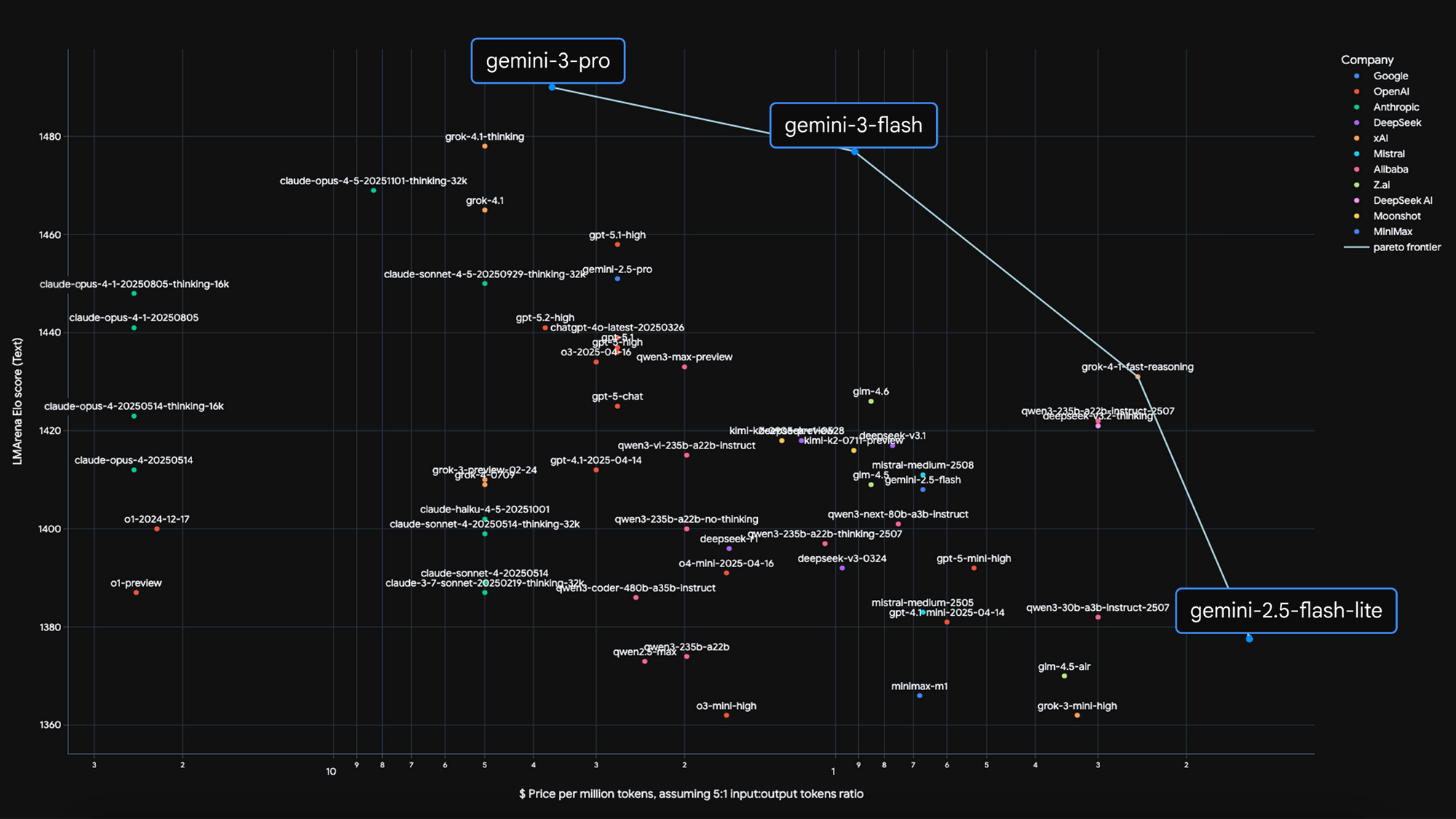
Flash 的真正亮点在于其卓越的速度和效率。它将模型质量、成本和速度的关系推向了一个新的“帕累托前沿”,即在不显著牺牲质量的情况下,实现了速度和成本的最佳平衡。
根据官方数据,Gemini 3 Flash 的响应速度大约是前代 Gemini 2.5 Pro 的 3 倍,而在处理典型任务时,平均消耗的 token 数量也减少了 30%。这种高效率使其非常适合需要快速反馈的场景。
为了更直观地展示,下表总结了两者在性能和效率上的核心差异:
| 特性 | Gemini 3 Flash | Gemini 3 Pro |
|---|---|---|
| 核心定位 | 速度、效率与成本效益 | 顶级性能与复杂推理 |
| 推理能力 | 接近 Pro 级别的推理能力 | 最前沿的推理与多模态能力 |
| 响应速度 | 极快,适合高频交互 | 较慢,专注于深度分析 |
| 资源消耗 | 低,平均 token 消耗少 30% | 较高,为复杂任务设计 |
| 核心优势 | 低延迟、低成本、高效率 | 极致的准确性和深度理解 |
成本与可用性
成本是决定一个模型能否被广泛应用的关键因素。Gemini 3 Flash 在这方面具有巨大优势,使得开发者和企业能够以更低的门槛使用前沿 AI 技术。
谷歌为 Gemini 3 Flash 提供了极具竞争力的定价策略,使其成为大规模部署的理想选择。
| 模型 | 输入定价 (每百万 token) | 输出定价 (每百万 token) |
|---|---|---|
| Gemini 3 Flash | $0.50 | $3.00 |
| Gemini 3 Pro | 更高 (具体请参考官方最新定价) | 更高 (具体请参考官方最新定价) |
注:音频输入定价可能有所不同。
在可用性方面,Gemini 3 Flash 已经广泛集成到谷歌的生态系统中。开发者可以通过 Gemini API、Google AI Studio、Vertex AI 和 Gemini Enterprise 等平台进行调用。对于普通用户,它已成为 Gemini App 和搜索引擎中 AI 模式的默认模型,这意味着数百万用户可以免费体验到 Gemini 3 的强大能力。
最佳应用场景
不同的设计哲学决定了 Flash 和 Pro 各自擅长的领域。
Gemini 3 Flash:高频与交互场景
Flash 的低延迟和低成本使其成为构建响应式、高交互性应用的首选。
- 实时编码助手:在 SWE-bench(一个评估编码代理能力的基准)上,Flash 获得了 78% 的高分,甚至超过了 Gemini 3 Pro。这使其非常适合在 IDE 中提供实时的代码补全、调试和重构建议。
- 交互式应用:例如,在游戏中充当实时 AI 助手,根据玩家的操作提供即时反馈;或者在设计工具中,根据设计师的草图快速生成多个 UI 设计方案并进行 A/B 测试。
- 快速多模态分析:你可以上传一段短视频,Flash 能在几秒内分析内容并提供改进建议(如优化高尔夫挥杆动作);或者上传一张图片,它能快速添加上下文 UI 覆盖,将静态图像变为交互式体验。
以下是一个简单的 Python 示例,展示了如何在代码中调用 Flash 模型:
import google.generativeai as genai
genai.configure(api_key="YOUR_API_KEY")
# 使用 Gemini 3 Flash 处理需要快速响应的任务
# 注意:'gemini-3-flash' 是示例模型名称,请以官方文档为准
flash_model = genai.GenerativeModel('gemini-3-flash')
# 任务:快速总结一张图片的内容
image_path = "path/to/your/image.jpg"
image_file = genai.upload_file(path=image_path)
prompt = "Describe what is happening in this image in one sentence."
response = flash_model.generate_content([prompt, image_file])
print(f"Flash Response: {response.text}")
Gemini 3 Pro:深度与复杂性场景
当任务的复杂性远超对速度的要求时,Gemini 3 Pro 便派上了用场。
- 深度科学研究:分析复杂的科学论文、处理海量数据集、进行高级别的数学和物理推理。
- 企业级战略分析:对复杂的财务报表、市场趋势报告进行深度剖析,提取关键洞察并预测未来风险。
- 创造性内容生成:撰写深度技术文档、创作长篇小说或剧本,这些任务需要模型具备强大的上下文理解和逻辑连贯性。
在这些场景下,Pro 能够投入更多计算资源进行深度“思考”,确保最终输出的准确性、深度和逻辑严密性。
如何选择?
总的来说,选择 Gemini 3 Flash 还是 Pro,取决于你的具体需求。
对于绝大多数需要与用户进行实时交互的应用,比如聊天机器人、内容摘要、实时数据分析等,Gemini 3 Flash 是更明智的选择。它的速度和成本优势将为你带来更好的用户体验和更低的运营开销。
当你面对的是没有严格时间限制、但对结果的准确性和深度要求极高的复杂任务时,那么 Gemini 3 Pro 及其更强大的“兄弟”模型(如 Gemini 3 Deep Think)将是你的不二之选。
最终,最佳实践可能是从 Gemini 3 Flash 开始构建你的应用。如果发现它在处理某些极端复杂的任务时能力不足,再平滑地切换到 Gemini 3 Pro,这样可以在性能和成本之间找到最佳的平衡点。
开发必备:API 全流程管理神器 Apifox
介绍完上文的内容,我想额外介绍一个对开发者同样重要的效率工具 —— Apifox。作为一个集 API 文档、API 调试、API 设计、API 测试、API Mock、自动化测试等功能于一体的 API 管理工具,Apifox 可以说是开发者提升效率的必备工具之一。
如果你正在开发项目需要进行接口调试,不妨试试 Apifox。注册过程非常简单,你可以直接在这里注册使用。
注册成功后可以先看看官方提供的示例项目,这些案例都是经过精心设计的,能帮助你快速了解 Apifox 的主要功能。
使用 Apifox 的一大优势是它完全兼容 Postman 和 Swagger 数据格式,如果你之前使用过这些工具,数据导入会非常方便。而且它的界面设计非常友好,即使是第一次接触的新手也能很快上手,快去试试吧!